This page provides a detailed account of the data cleaning section, which serves as the foundation for subsequent EDA and modeling analysis. It should be noted that data cleaning is an iterative process, whereby the section may be revisited on numerous occasions as the project progresses, with content continually added and optimized.
Data Cleaning Process
Below is the process description of data cleaning. Corresponding visualizations, such as heatmaps and box plots, are generated and displayed in the code section.
1. Data Type Correction and Formatting
Given the considerable number of raw datasets (totally 31 datasets) and the subsequent necessity of synthesizing the processed datasets required for analysis, we advanced the processing of the data types. The raw data types are all objects, and the date columns were converted to the date format, while all other columns were converted to the floating point format. This format meets the subsequent needs for data analysis.
2. Feature Engineering
In order to ensure consistency in the presentation of foreign exchange data, all FX values were converted to U.S. dollar-based calculations. Subsequently, the calculation of cryptocurrency return rates and FX percentage changes was performed using the adjusted closed price. Data frames were generated with dates as rows, cryptocurrency names or FX names as columns, and return rates or percentage changes as cell values.
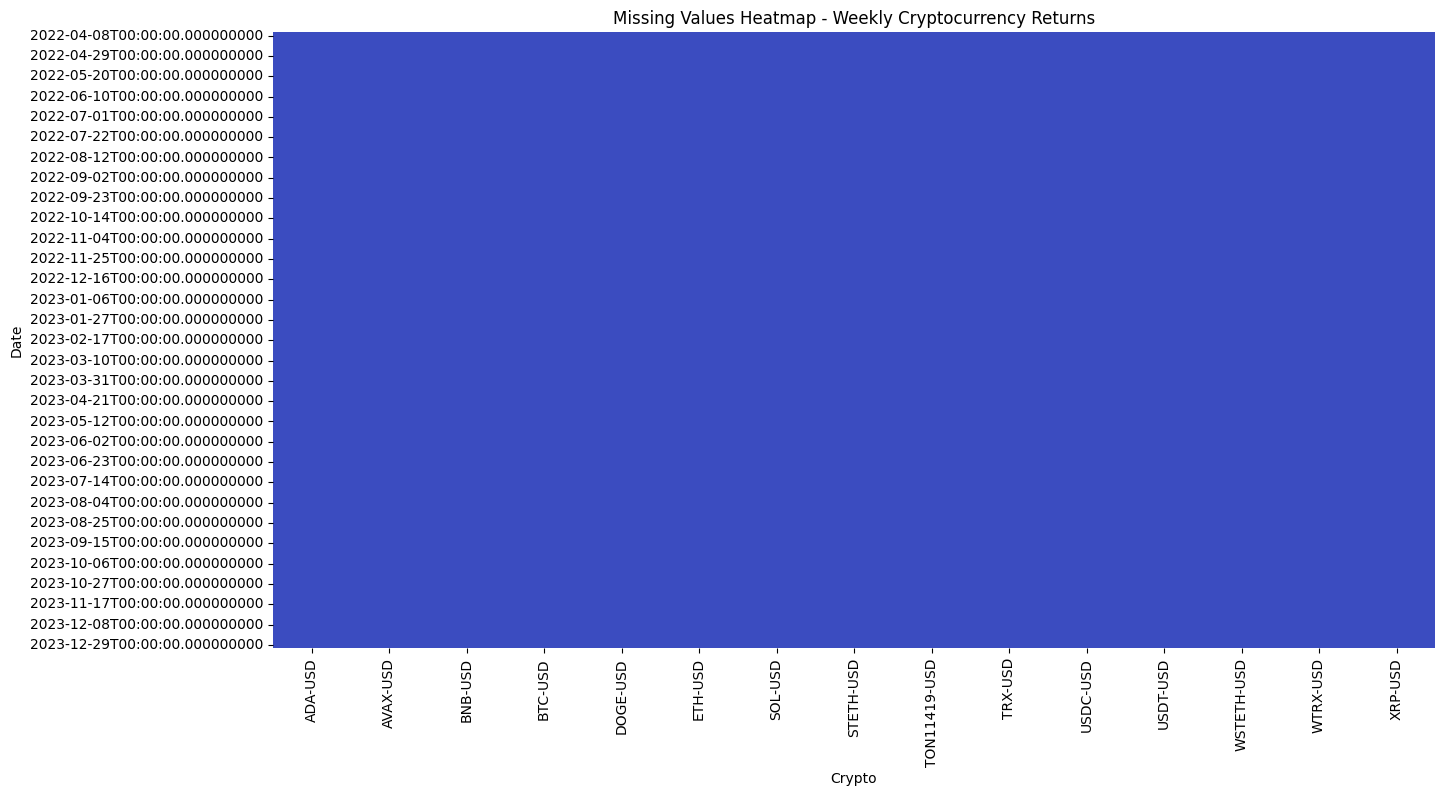
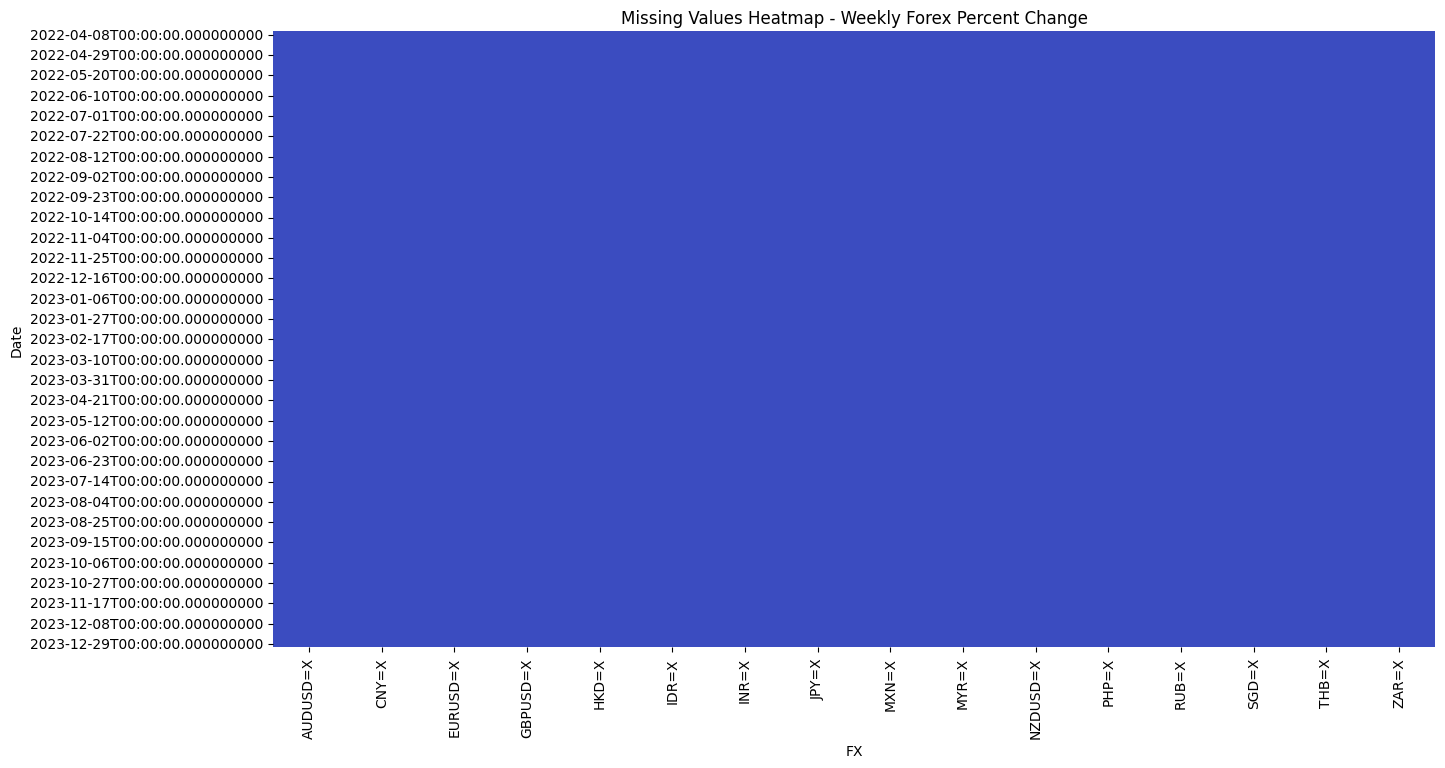
3. Managing Missing Data
Given the enhanced stability and reliability of the data sources, it is anticipated that the number of missing values will be minimal. Consequently, we elected to utilize the heat map visualization as a rapid mean of identifying the presence of missing values and their respective locations.
Crypto Data: A preliminary examination of the datasets revealed that certain cryptocurrencies have data beginning after January 1, 2019. The sole instance of anomalous missing values was observed for AVAX-USD, for which data for the interval between July 15 and September 21, 2020, was entirely absent. This was subsequent to the availability of price data solely for July 13 and 14, 2020. Consequently, the decision was taken to remove the data for the 13th and 14th, and to establish the data commencement for AVAX-USD as September 22, 2020. Subsequently, the data inception dates for all cryptocurrencies were documented for subsequent analysis.
Forex Data: The heat map revealed a mere two instances of missing data, prompting the decision to employ a method of filling in the missing values. This entailed the use of the average perncent change for the two days preceding and succeeding the aforementioned date.
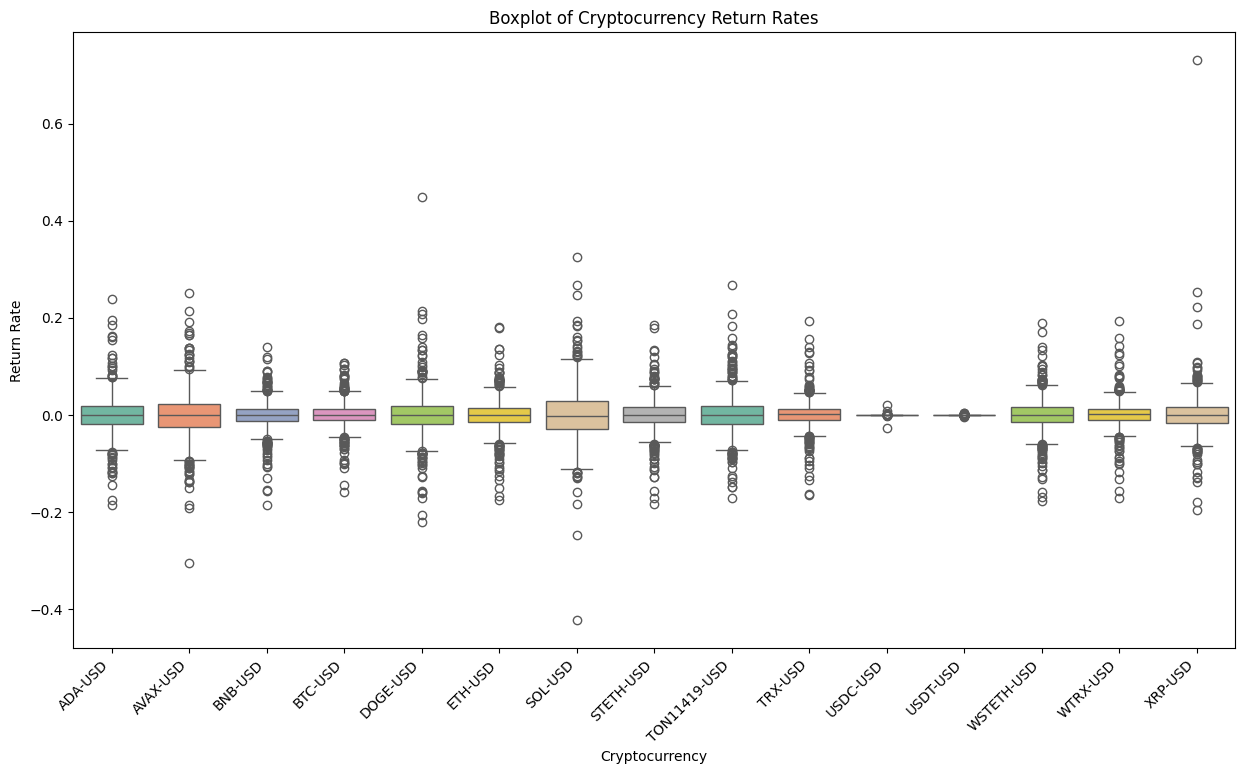
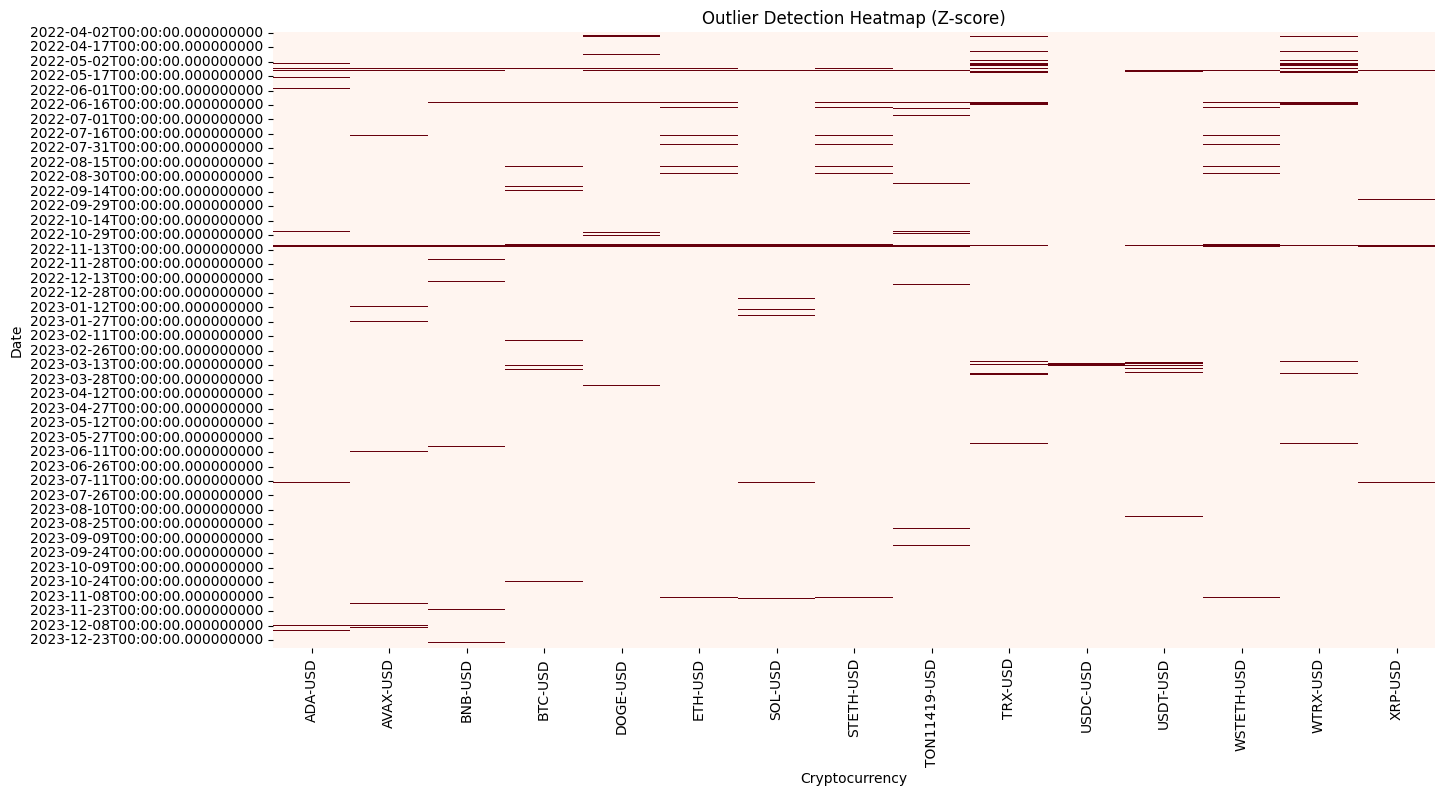
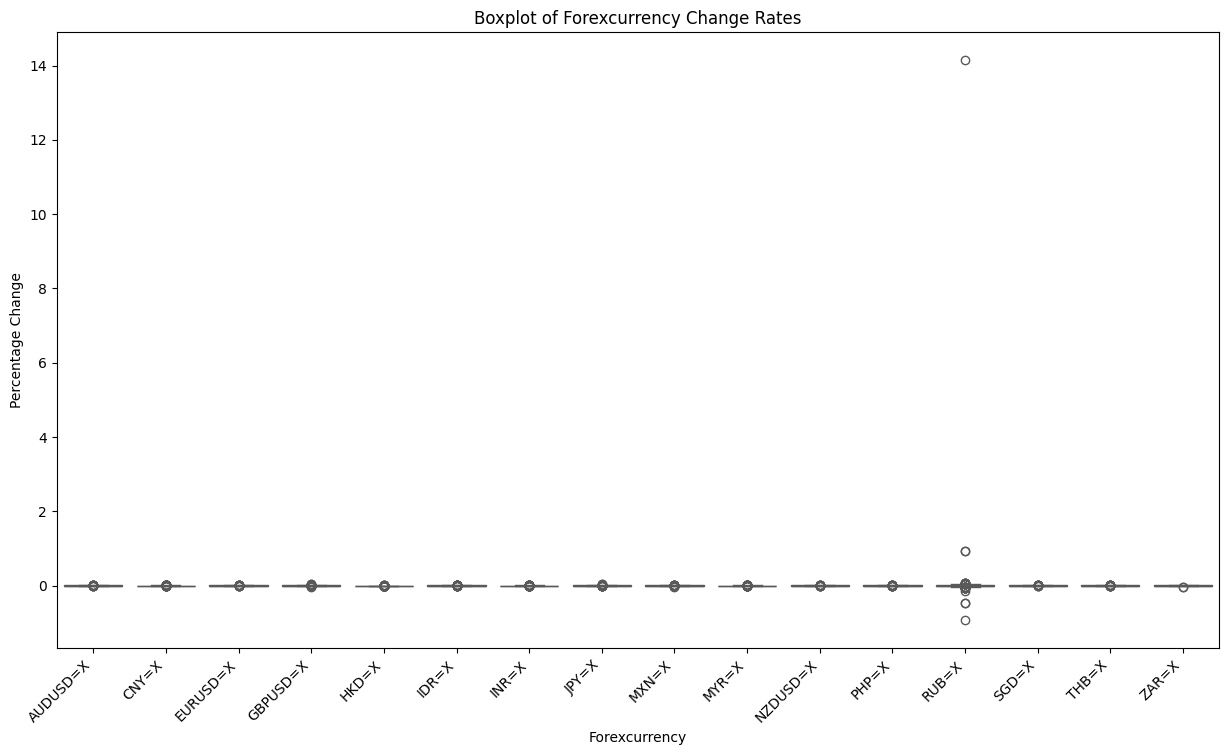
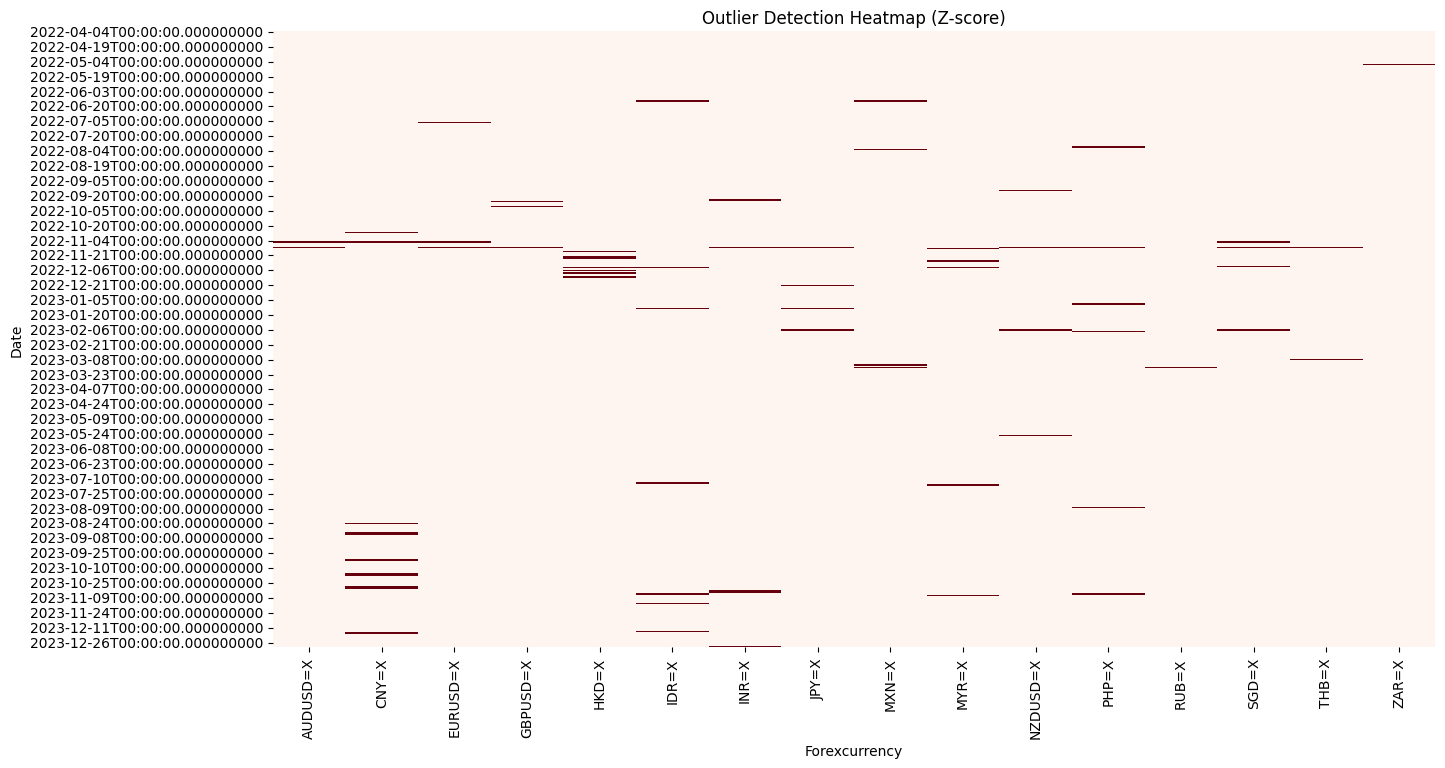
4. Outlier Detection and Treatment
In light of the project’s research objectives and the intrinsic characteristics of financial markets, it is our contention that extreme returns or volatility changes should be retained, as they may serve to reflect the effects of market volatility that we are interested in. Accordingly, this section employs a combination of z-score and heatmap methodologies to identify and localize outliers.
5. Data Correction & Adjustment
During the data validation process, it was discovered that the adjusted close price of SHIB-USD was 0 until April 16, 2021. This is likely due to the fact that the long-term price of SHIB is lower than the supported precision of Yahoo Finance. In light of the fact that all subsequent prices are exceedingly low and volatile, it seems prudent to consider replacing the cryptocurrency. Its market share is only 14th among the acquired cryptocurrencies and does not exert a decisive influence on the dataset. Therefore, we posit that replacing it with the cryptocurrency TON11419, which has a similar market share but more reliable price data, represents the optimal solution. The new dataset has been collected, cleaned, and will be utilized in subsequent analysis.
In the subsequent analysis, we found that due to the prolonged absence of some cryptocurrency data, we had to narrow down the data range to avoid affecting the application or results of some analysis techniques sensitive to missing values. Since the amount of data is still sufficient, we have decided to modify the starting time of data collection so that all cryptocurrencies have full raw data.
In addition, in our subsequent EDA and unsupervised learning analysis, we found that due to the complexity of financial market data itself, it was difficult to find significant patterns and results in daily volatility research. We decided to expand the generation of weekly datasets for subsequent analysis. Similar cleaning and finishing steps are applied.
Code
# Import needed packagesimport pandas as pdimport osimport warningsimport seaborn as snsimport matplotlib.pyplot as pltfrom scipy import stats# Suppress SettingWithCopyWarningwarnings.filterwarnings("ignore", category=pd.errors.SettingWithCopyWarning)warnings.filterwarnings("ignore", category=RuntimeWarning)# Define cleaning function of crypto datadef clean_crypto_data(df):# Step1: Adjust the structure df = df.iloc[2:] df.reset_index(drop=True, inplace=True) df.rename(columns={'Price': 'Date', 'Adj Close': 'Adj_Close'}, inplace=True)# Step2: Convert data types numeric_cols = ['Adj_Close', 'Close', 'High', 'Low', 'Open', 'Volume'] df[numeric_cols] = df[numeric_cols].apply(pd.to_numeric, errors='coerce') df['Date'] = pd.to_datetime(df['Date'], errors='coerce')# Step3: Get return rate df['Return_Rate'] = df['Adj_Close'].pct_change()return df# Process all crypto CSV filescrypto_list = ["BTC-USD", "ETH-USD", "XRP-USD", "USDT-USD", "SOL-USD", "BNB-USD", "DOGE-USD", "ADA-USD", "USDC-USD", "STETH-USD", "WTRX-USD", "TRX-USD","AVAX-USD", "WSTETH-USD", "TON11419-USD"]crypto_data_combined = pd.DataFrame()for symbol in crypto_list: file_path =f'../../data/raw-data/{symbol}.csv' df = pd.read_csv(file_path) df_cleaned = clean_crypto_data(df) df_cleaned['Crypto'] = symbol# Append to combined DataFrame crypto_data_combined = pd.concat([crypto_data_combined, df_cleaned], ignore_index=True)crypto_data_combined.head()# Subset the combined DataFrame for Return_Rate and reshape itcrypto_returns = crypto_data_combined.pivot_table( index='Date', columns='Crypto', values='Return_Rate')# Check missing values if any through visualizationdef visualize_missing_values(df): plt.figure(figsize=(15, 8)) sns.heatmap(df.isna(), cbar=False, cmap='viridis') plt.title("Missing Values Heatmap") plt.show()visualize_missing_values(crypto_returns)# # Handle missing values# crypto_returns.loc['2020-07-14', 'AVAX-USD'] = float('nan')# visualize_missing_values(crypto_returns)# # Define each crypto's start date# def check_start_dates(df, crypto_list):# for crypto in crypto_list:# crypto_data = df[crypto].dropna()# if not crypto_data.empty:# start_date = crypto_data.index.min()# print(f"{crypto}: Start Date = {start_date}")# else:# print(f"{crypto}: No data available.")# check_start_dates(crypto_returns, crypto_list)# Check data types and convert if neededcrypto_returns_reset = crypto_returns.reset_index()print(crypto_returns_reset.dtypes)# Check Outliers by visualizationdef visualize_outliers(df): plt.figure(figsize=(15, 8)) sns.boxplot(data=df, palette="Set2") plt.title("Boxplot of Cryptocurrency Return Rates") plt.xlabel("Cryptocurrency") plt.ylabel("Return Rate") plt.xticks(rotation=45, ha='right', fontsize=10) plt.show()visualize_outliers(crypto_returns)# Visualize Outliers as Heatmapdef visualize_outliers_heatmap(df, threshold=3): z_scores = stats.zscore(df, nan_policy='omit') outlier_mask =abs(z_scores) > threshold plt.figure(figsize=(15, 8)) sns.heatmap(outlier_mask, cmap='Reds', cbar=False) plt.title("Outlier Detection Heatmap (Z-score)") plt.xlabel("Cryptocurrency") plt.ylabel("Date") plt.show()visualize_outliers_heatmap(crypto_returns)# Save cleaned dataprint(crypto_returns.head())cleaned_filepath ='../../data/processed-data/crypto_returns_cleaned.csv'crypto_returns.to_csv(cleaned_filepath)
import numpy as np# Function for Weekly Returnsdef calculate_weekly_returns(df, value_col, date_col='Date'): df[date_col] = pd.to_datetime(df[date_col]) weekly_returns = ( df.set_index(date_col)[value_col] .resample('W-FRI') .last() .pct_change() )return weekly_returns.reset_index()# Weekly Aggregation for Crypto Dataweekly_crypto = pd.DataFrame()for symbol in crypto_list: crypto_weekly = calculate_weekly_returns( crypto_data_combined[crypto_data_combined['Crypto'] == symbol],'Adj_Close' ) crypto_weekly['Crypto'] = symbol weekly_crypto = pd.concat([weekly_crypto, crypto_weekly], ignore_index=True)weekly_crypto_returns = weekly_crypto.pivot_table( index='Date', columns='Crypto', values='Adj_Close')weekly_crypto_returns = weekly_crypto_returns.drop(weekly_crypto_returns.index[-1])# Save Weekly Cryptocurrency Dataweekly_crypto_filepath ='../../data/processed-data/weekly_crypto_returns.csv'weekly_crypto_returns.to_csv(weekly_crypto_filepath)# Weekly Aggregation for Forex Dataweekly_fx = pd.DataFrame()for symbol in fx_list: fx_weekly = calculate_weekly_returns( fx_data_combined[fx_data_combined['FX'] == symbol],'Adj_Close' ) fx_weekly['FX'] = symbol weekly_fx = pd.concat([weekly_fx, fx_weekly], ignore_index=True)weekly_fx_rates = weekly_fx.pivot_table( index='Date', columns='FX', values='Adj_Close')# Save Weekly Forex Dataweekly_fx_filepath ='../../data/processed-data/weekly_fx_rates.csv'weekly_fx_rates.to_csv(weekly_fx_filepath)# Visualization Checkdef visualize_weekly_data(df, title): plt.figure(figsize=(15, 8)) sns.heatmap(df.isna(), cmap='coolwarm', cbar=False) plt.title(f"Missing Values Heatmap - {title}") plt.show()visualize_weekly_data(weekly_crypto_returns, "Weekly Cryptocurrency Returns")visualize_weekly_data(weekly_fx_rates, "Weekly Forex Percent Change")
The raw and cleaned datasets are stored locally in the following folders: Raw Data: ../../data/raw-data/ Cleaned Data: ../../data/processed-data/
Note: These directories are part of the local project repository and are excluded from version control on GitHub. They are included here for reference only and will not be accessible externally.