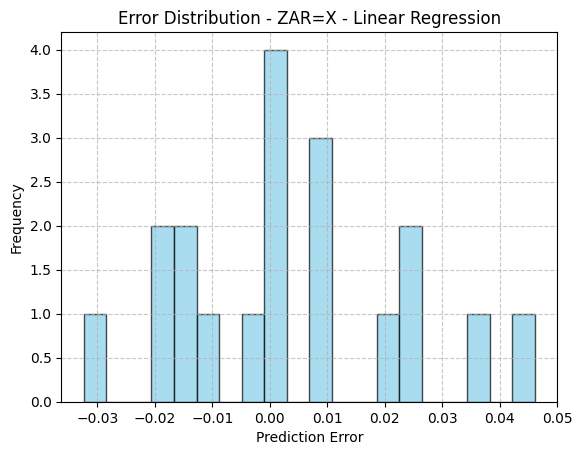
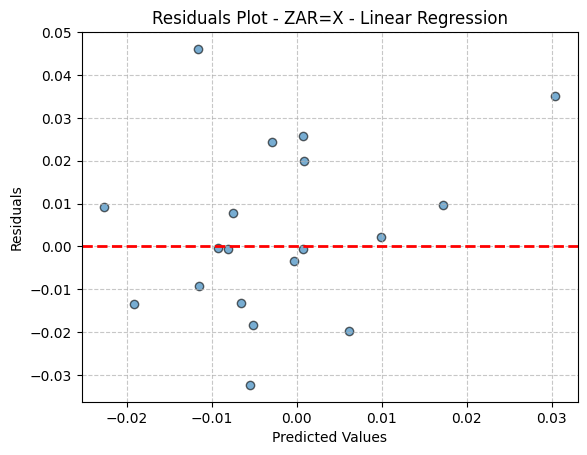
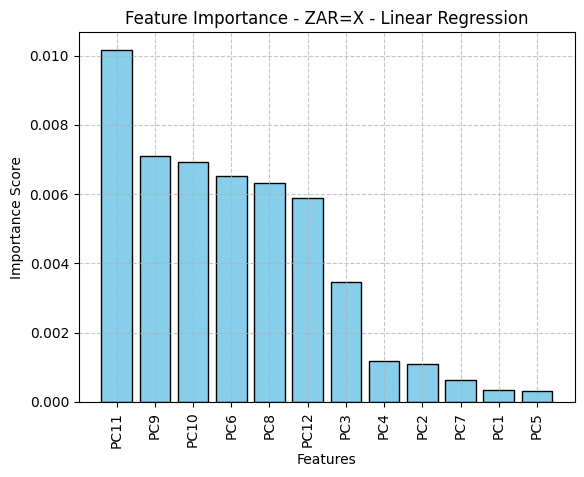
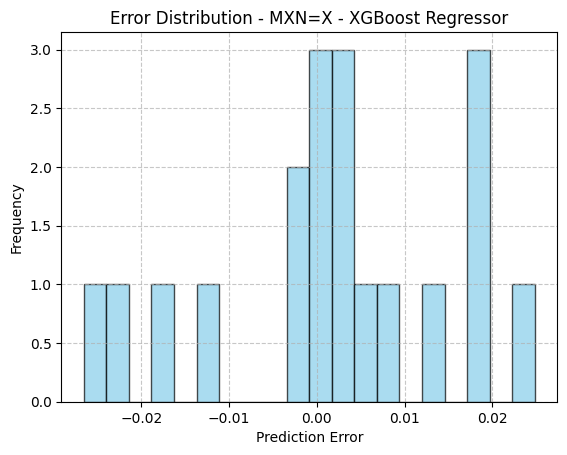
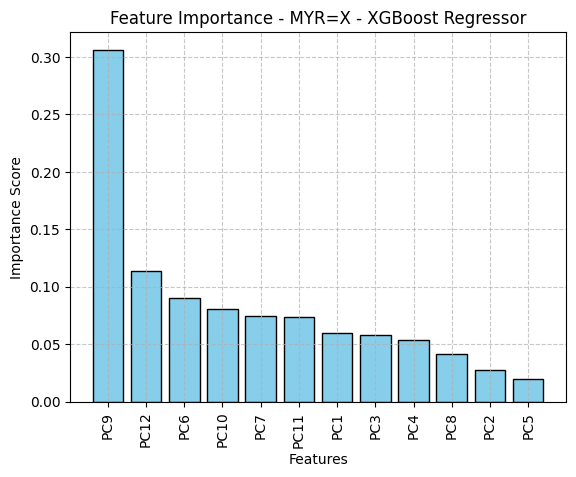
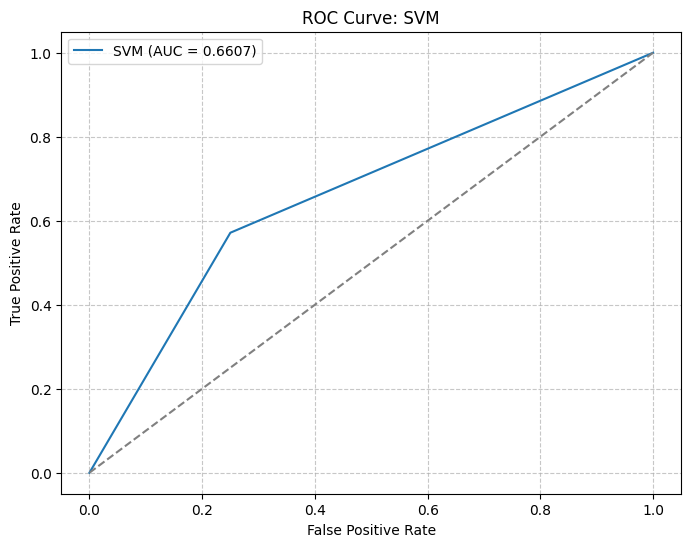
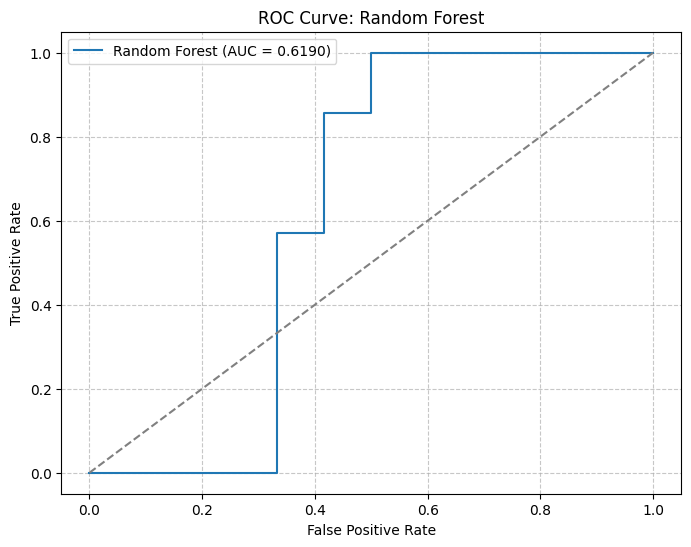
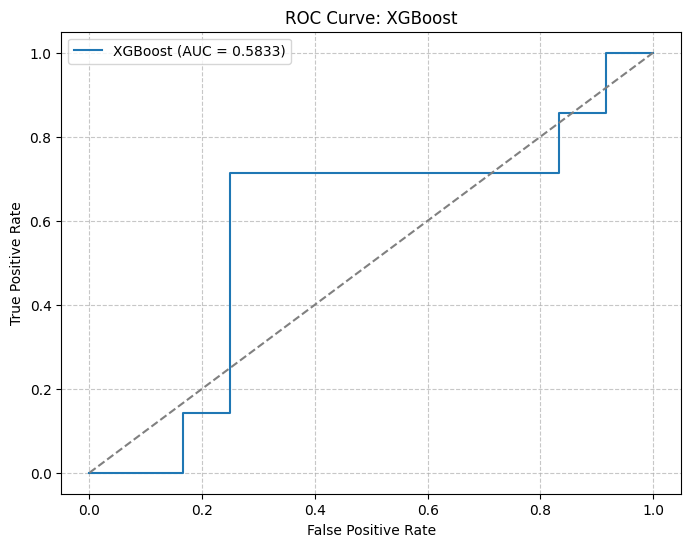
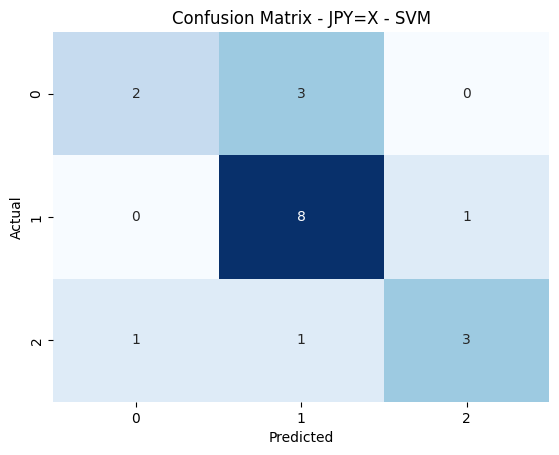
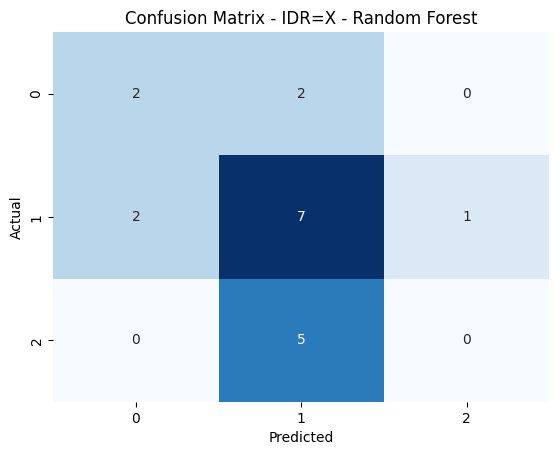
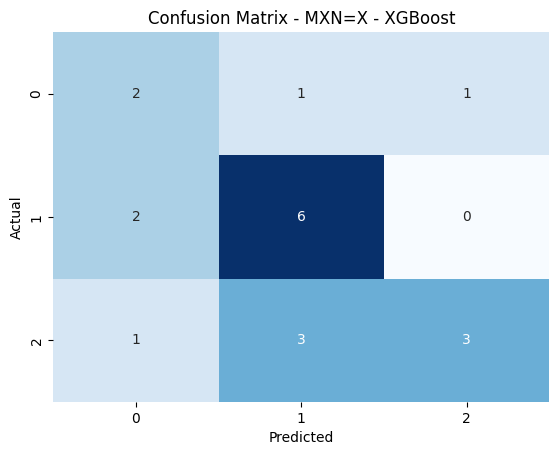
PCA: 2 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.0640
PCA: 2 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.0640
PCA: 2 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.0645
PCA: 2 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.0692
PCA: 2 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 2 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 2 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 2 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.0825
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1015
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0517
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0940
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: -0.0865
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0221
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0217
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0544
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0697
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0184
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0486
PCA: 2 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0257
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0740
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1650
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1524
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2058
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2061
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2007
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0862
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0946
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.3520
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2770
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0944
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1175
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0202
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1088
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1111
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1457
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2662
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2006
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0861
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0946
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.3520
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2770
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0944
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1175
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0693
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1657
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0975
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1008
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2662
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2006
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0861
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0946
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.3520
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2770
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0944
PCA: 2 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1175
PCA: 3 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1507
PCA: 3 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1504
PCA: 3 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1477
PCA: 3 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1283
PCA: 3 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 3 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 3 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 3 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.0121
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0017
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0739
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0170
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0412
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0064
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0361
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0488
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0378
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0461
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0335
PCA: 3 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0171
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1084
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1284
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1851
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1398
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1920
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0268
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0988
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0255
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1609
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0077
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0815
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0143
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1290
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1205
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1622
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0890
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1930
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0269
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0988
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0255
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1609
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0077
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0815
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0143
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2119
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1013
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0968
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0099
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1930
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0269
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0988
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0255
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1609
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0077
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0815
PCA: 3 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0143
PCA: 4 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.2269
PCA: 4 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.2264
PCA: 4 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.2223
PCA: 4 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1908
PCA: 4 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 4 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 4 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 4 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.1189
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0732
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0290
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0351
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0103
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0434
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0903
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0240
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0151
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0275
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0379
PCA: 4 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0405
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0730
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0771
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0496
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0379
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.3679
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0374
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0365
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1056
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2309
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0953
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0258
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0954
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0783
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0597
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0280
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0320
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.3655
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0374
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0365
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1056
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2309
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0953
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0258
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0954
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2084
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0277
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0336
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1065
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.3655
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0374
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0365
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1056
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.2309
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0953
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0258
PCA: 4 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0954
PCA: 5 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.2340
PCA: 5 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.2334
PCA: 5 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.2276
PCA: 5 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1848
PCA: 5 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 5 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 5 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 5 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.0398
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0423
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0427
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0632
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0374
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0126
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1320
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0422
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0931
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0535
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0658
PCA: 5 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0578
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0615
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0043
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0485
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0499
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1166
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0759
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0668
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1345
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0230
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0167
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0677
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0640
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0076
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0469
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0762
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0638
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1096
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0759
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0668
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1345
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0230
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0167
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0677
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0640
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0334
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1026
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0319
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1363
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1096
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0759
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0668
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1345
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0230
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0167
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0677
PCA: 5 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0640
PCA: 6 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1659
PCA: 6 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1654
PCA: 6 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1610
PCA: 6 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1298
PCA: 6 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 6 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 6 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 6 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.1040
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1093
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0707
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0075
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.1102
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0635
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1510
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.1326
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0989
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0898
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1106
PCA: 6 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.1037
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0556
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0178
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0739
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0397
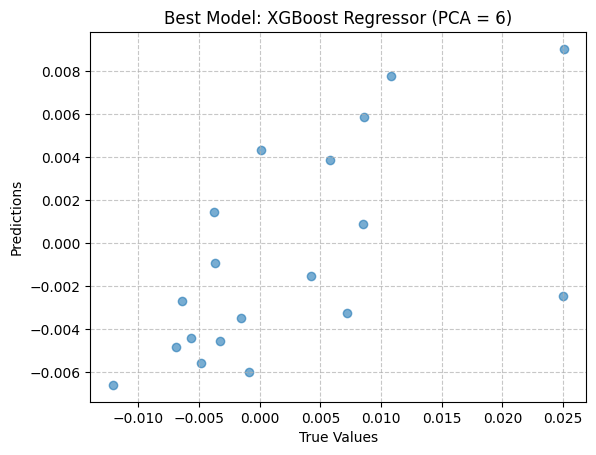
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1492
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1839
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0135
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0466
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0056
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.2590
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0325
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0826
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0295
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0559
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0666
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0306
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1411
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1839
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0135
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0466
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0056
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.2590
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0325
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0826
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0967
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1428
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0231
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0525
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1411
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1839
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: 0.0135
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0466
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0056
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.2590
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0325
PCA: 6 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0826
PCA: 7 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.0972
PCA: 7 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.0969
PCA: 7 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.0939
PCA: 7 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.0745
PCA: 7 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 7 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 7 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 7 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.0814
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0476
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0041
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0972
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0644
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0382
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0651
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0222
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0615
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0612
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0765
PCA: 7 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0706
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0614
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0441
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0749
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0319
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0434
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0417
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1236
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0235
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0684
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0592
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0512
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0018
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0066
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1068
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1003
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0566
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0496
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0417
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1236
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0234
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0684
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0592
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0512
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0018
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0460
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.1395
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0715
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0226
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0496
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0417
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1236
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0234
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0684
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0592
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0512
PCA: 7 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0018
PCA: 8 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.0715
PCA: 8 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.0712
PCA: 8 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.0681
PCA: 8 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.0515
PCA: 8 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 8 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 8 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 8 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.0396
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0308
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.1003
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0739
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0372
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0460
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0621
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.1152
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0750
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0659
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0589
PCA: 8 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0573
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0609
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0463
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1171
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0137
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1187
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0673
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1339
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0233
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1008
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0008
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0723
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0423
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0054
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0186
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1434
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0347
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1135
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0673
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1339
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0233
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1008
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0008
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0723
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0423
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0989
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0176
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1150
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0323
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1135
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0673
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1339
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0233
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.1008
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0008
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0723
PCA: 8 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0423
PCA: 9 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.0003
PCA: 9 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.0004
PCA: 9 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.0014
PCA: 9 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.0107
PCA: 9 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 9 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 9 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 9 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.1474
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1170
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0481
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0934
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: -0.0253
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0695
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1102
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0846
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0813
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0735
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0220
PCA: 9 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0632
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1864
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3820
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.3518
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.3805
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1061
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3115
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.5124
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.3116
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1489
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3623
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0002 | R²: -0.6279
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.4410
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1475
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.4005
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.4519
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.3907
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1059
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3115
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.5124
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.3116
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1489
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3623
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0002 | R²: -0.6279
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.4410
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1854
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.4184
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.4730
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.3657
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1059
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3115
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.5124
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.3116
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1489
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.3623
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0002 | R²: -0.6279
PCA: 9 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.4410
PCA: 10 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: 0.0015
PCA: 10 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: 0.0015
PCA: 10 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: 0.0022
PCA: 10 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.0008
PCA: 10 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 10 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 10 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 10 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.0219
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0385
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0275
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0538
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: -0.0431
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0304
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0047
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0142
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0428
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0467
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0191
PCA: 10 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0478
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0683
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0298
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1092
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0936
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0039
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0024
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1460
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0769
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0269
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0988
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1538
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0761
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0923
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0005
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1628
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0943
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0038
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0025
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1460
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0768
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0269
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0988
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1538
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0761
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0944
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0156
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1585
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0707
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0038
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0025
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1460
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0768
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0269
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0988
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1538
PCA: 10 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0761
PCA: 11 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: 0.0937
PCA: 11 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: 0.0931
PCA: 11 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: 0.0873
PCA: 11 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: 0.0465
PCA: 11 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 11 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 11 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 11 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.0678
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0110
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0164
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0325
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0487
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0436
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0107
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0088
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0179
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0445
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0144
PCA: 11 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0029
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0428
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0433
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0630
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0465
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0457
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0471
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1514
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0626
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0133
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0084
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1066
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1012
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0544
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0036
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0903
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0311
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0457
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0471
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1514
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0626
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0133
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0084
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1066
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1012
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0713
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0219
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1218
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0500
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0457
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0471
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1514
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0626
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0133
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0084
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1066
PCA: 11 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1012
PCA: 12 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: 0.0936
PCA: 12 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: 0.0930
PCA: 12 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: 0.0873
PCA: 12 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: 0.0462
PCA: 12 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 12 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 12 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 12 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.0318
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0375
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0077
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0241
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: -0.0458
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0215
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0208
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0118
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0321
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0356
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0005
PCA: 12 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0056
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0842
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0711
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1534
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1414
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0952
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0641
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2622
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2554
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0998
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1394
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2459
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1721
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0947
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0786
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1760
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1542
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0952
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0640
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2621
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2553
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0998
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1394
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2459
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1721
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1053
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0882
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2080
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2040
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0952
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0640
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2621
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2553
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0998
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1394
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2459
PCA: 12 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1721
PCA: 13 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: 0.0805
PCA: 13 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: 0.0834
PCA: 13 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: 0.0848
PCA: 13 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: 0.0458
PCA: 13 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 13 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 13 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 13 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.0852
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0557
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0370
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0083
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: -0.0239
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0859
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0502
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0406
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0223
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0778
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0242
PCA: 13 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0421
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1185
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1308
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1321
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1313
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0659
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2277
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2369
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2293
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1606
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1949
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1580
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1601
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1176
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1784
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2145
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1771
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0660
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2276
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2369
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2293
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1606
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1949
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1580
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1601
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1624
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2035
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2404
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2090
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0660
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2276
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2369
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2293
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1606
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1949
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1580
PCA: 13 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1601
PCA: 14 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: 0.0901
PCA: 14 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: 0.0912
PCA: 14 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: 0.0873
PCA: 14 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: 0.0461
PCA: 14 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 14 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 14 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 14 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: -0.0912
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0232
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0406
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0387
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0104
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0478
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0032
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0295
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: -0.0070
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0390
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0178
PCA: 14 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0419
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1176
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1037
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1315
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1313
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0486
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1442
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2910
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2731
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1015
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1903
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2488
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1639
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1329
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1309
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2108
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2180
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0487
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1442
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2910
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2731
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1015
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1903
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2488
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1639
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1076
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1375
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2415
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2433
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0487
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1442
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2910
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.2731
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1015
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1903
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.2488
PCA: 14 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1639
PCA: 15 | Model: Ridge Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: 0.0936
PCA: 15 | Model: Ridge Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: 0.0936
PCA: 15 | Model: Ridge Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: 0.0878
PCA: 15 | Model: Ridge Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: 0.0461
PCA: 15 | Model: Lasso Regression | Params: {'alpha': 0.01} | MSE: 0.0001 | R²: -0.1439
PCA: 15 | Model: Lasso Regression | Params: {'alpha': 0.1} | MSE: 0.0001 | R²: -0.1439
PCA: 15 | Model: Lasso Regression | Params: {'alpha': 1} | MSE: 0.0001 | R²: -0.1439
PCA: 15 | Model: Lasso Regression | Params: {'alpha': 10} | MSE: 0.0001 | R²: -0.1439
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': None} | MSE: 0.0001 | R²: 0.0367
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0492
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0074
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 100, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0010
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': None} | MSE: 0.0001 | R²: 0.0543
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 5} | MSE: 0.0001 | R²: 0.0483
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0169
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 200, 'max_depth': 20} | MSE: 0.0001 | R²: -0.0067
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': None} | MSE: 0.0001 | R²: 0.0324
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 5} | MSE: 0.0001 | R²: -0.0434
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 10} | MSE: 0.0001 | R²: 0.0089
PCA: 15 | Model: Random Forest Regressor | Params: {'n_estimators': 500, 'max_depth': 20} | MSE: 0.0001 | R²: 0.0148
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.1103
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1168
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1353
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1090
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0432
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1448
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1417
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0932
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0376
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2728
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0930
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 100, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0749
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0373
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1431
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1471
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1366
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0430
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1448
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1416
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0931
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0376
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2728
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0930
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0749
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0151
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1384
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1597
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.01, 'max_depth': 10} | MSE: 0.0001 | R²: -0.1263
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 3} | MSE: 0.0001 | R²: 0.0430
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 5} | MSE: 0.0001 | R²: -0.1448
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 7} | MSE: 0.0001 | R²: -0.1416
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.1, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0931
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 3} | MSE: 0.0001 | R²: -0.0376
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 5} | MSE: 0.0001 | R²: -0.2728
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 7} | MSE: 0.0001 | R²: -0.0930
PCA: 15 | Model: XGBoost Regressor | Params: {'n_estimators': 500, 'learning_rate': 0.2, 'max_depth': 10} | MSE: 0.0001 | R²: -0.0749
Best Model: XGBoost Regressor | PCA Components: 6 | Params: {'n_estimators': 200, 'learning_rate': 0.2, 'max_depth': 5} | R²: 0.2590