This page serves to illustrate the descriptions and technical details of the Unsupervised Machine Learning section. The objective of this section is to investigate the underlying patterns and cluster classes of the data through the use of downscaling and clustering techniques, with the aim of identifying suitable methods for categorizing the data and providing an analytical foundation for subsequent supervised learning.
Dimensionality Reduction
The level of data dimensionality has a direct impact on the efficiency of data analysis and modeling, particularly in the context of multivariate financial data. An excessive level of dimensionality may result in the introduction of an overwhelming amount of noise, thereby increasing the complexity of the model to a considerable extent. The application of dimensionality reduction techniques can effectively reduce the dimensionality of features while retaining as much pertinent information in the data as possible. This provides a more effective analytical basis for subsequent identification of data patterns and cluster classes.
In this section, two distinct methods for dimensionality reduction are employed: principal component analysis (PCA) and t-distributed stochastic neighbor embedding (tSNE). Principal component analysis is a linear dimensionality reduction technique that generates principal components by capturing the direction of the largest variance in the data, thereby transforming the data from a high-dimensional to a low-dimensional space. t-SNE is a nonlinear dimensionality reduction technique, which is capable of capturing complex nonlinear structures in the data. Furthermore, it is visualization-friendly and suitable for discovering local patterns in the data.
Principal component analysis (PCA)
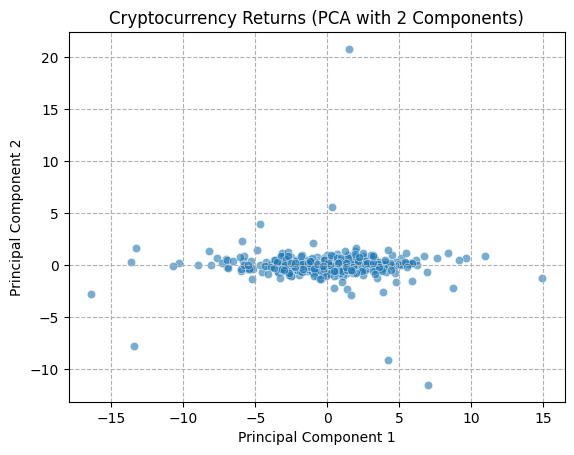
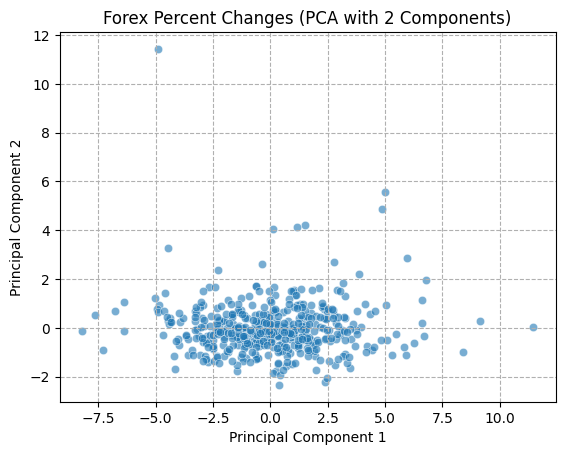
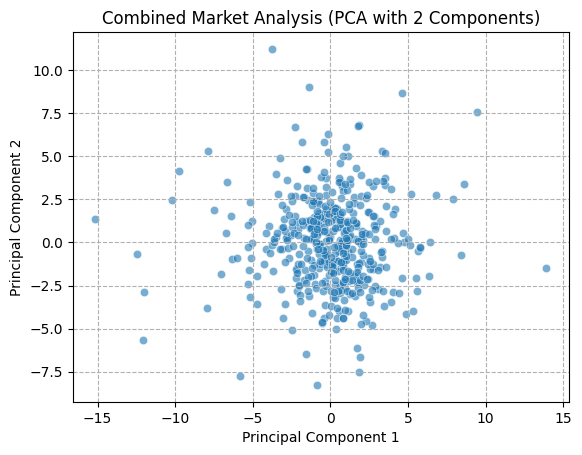
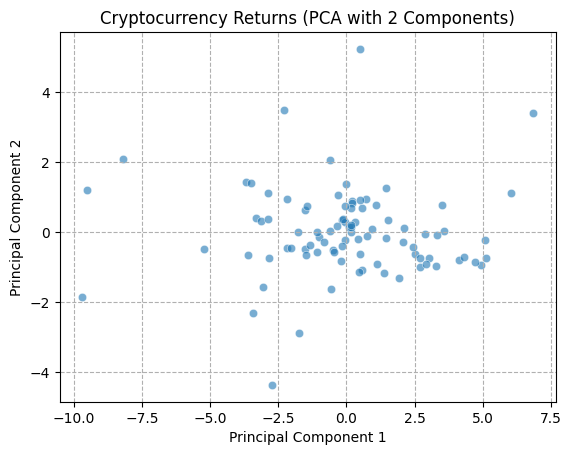
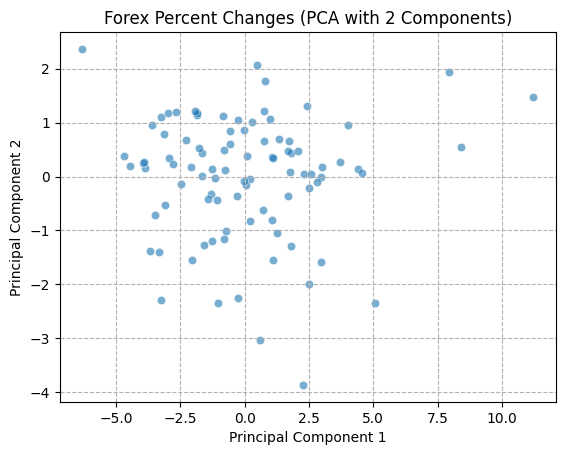
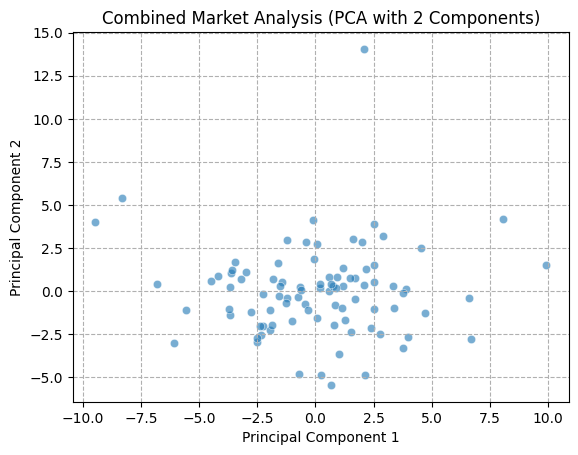
The PCA technique necessitates the calculation of a covariance matrix, therefore it is essential that the data utilized be complete and devoid of any missing values. We have confirmed that there are no missing values in the data during data cleaning, so we can directly use the cleaned datasets. Furthermore, the selected timeframe is more focused on recent market conditions. Once the scope of the data had been confirmed, the decision was taken to apply the PCA technique to three aspects of the data: within the cryptocurrency market, within the FX market, and the cryptocurrency combined with the FX market.
A function was defined for the purpose of visualizing the first two principal components of the data, with the objective of demonstrating the state of the data in two-dimensional space in the form of a scatter plot. First, the data were normalized to prevent any bias in the results of the PCA analysis that might result from significant differences in the range of eigenvalues. All volatility columns, with the exception of the date column, were standardized using the StandardScaler function, with the objective of ensuring that the mean value of the data was 0 and the standard deviation was 1.
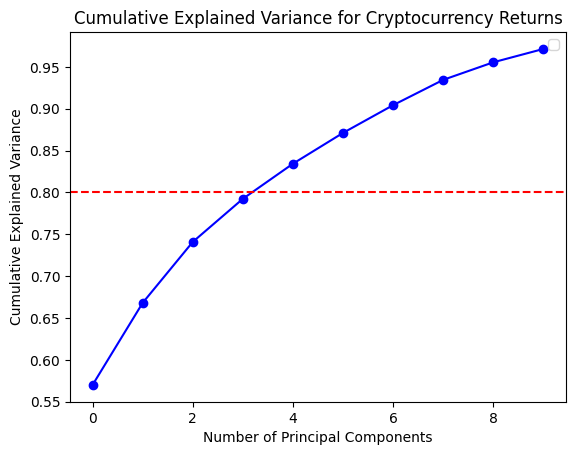
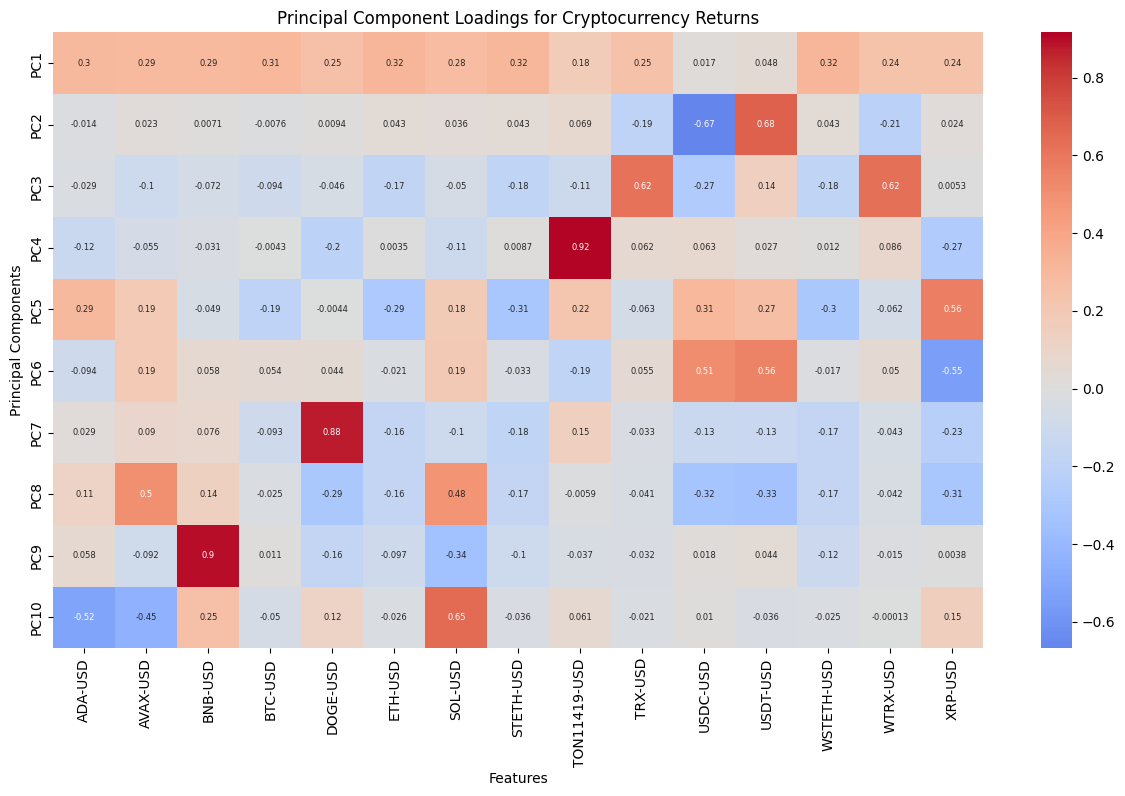
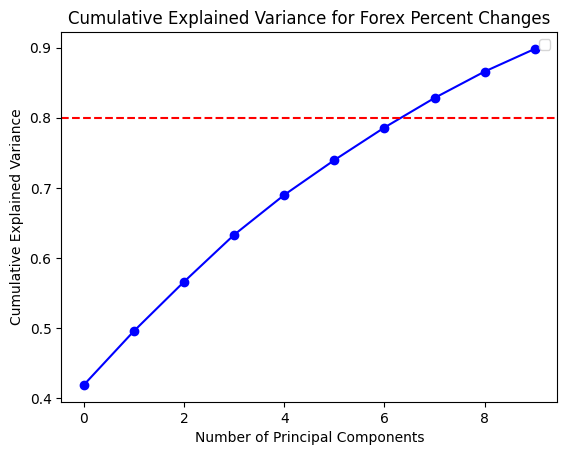
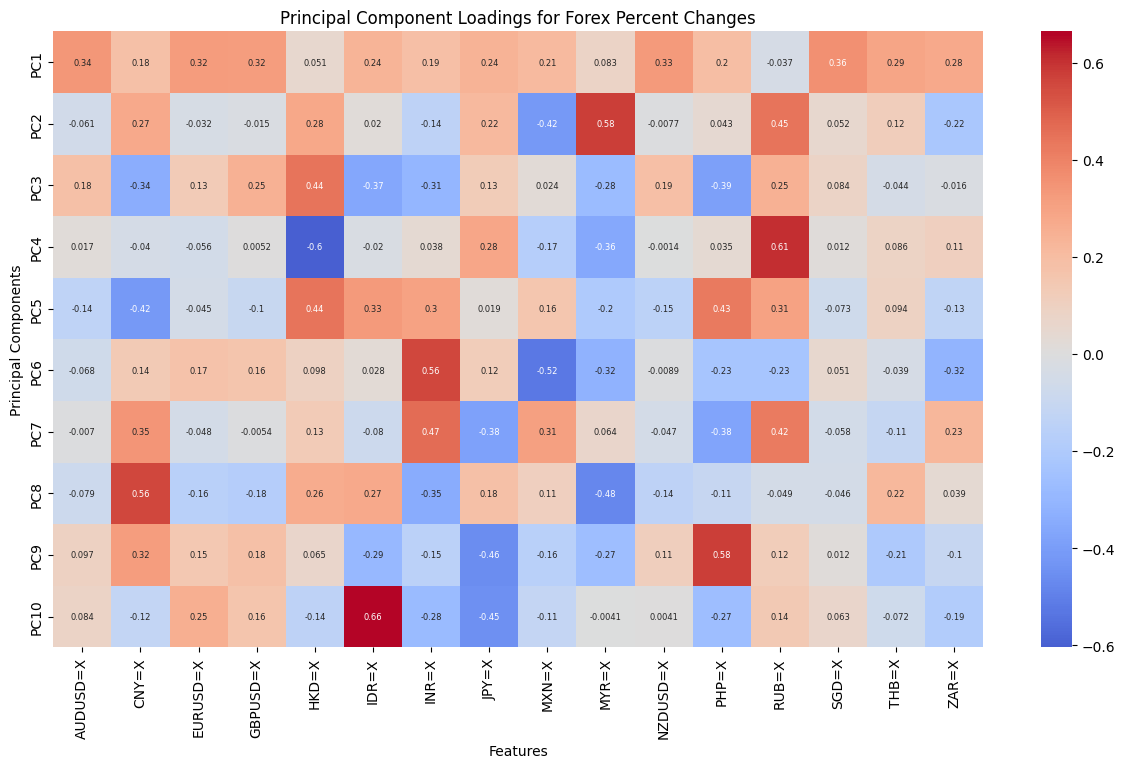
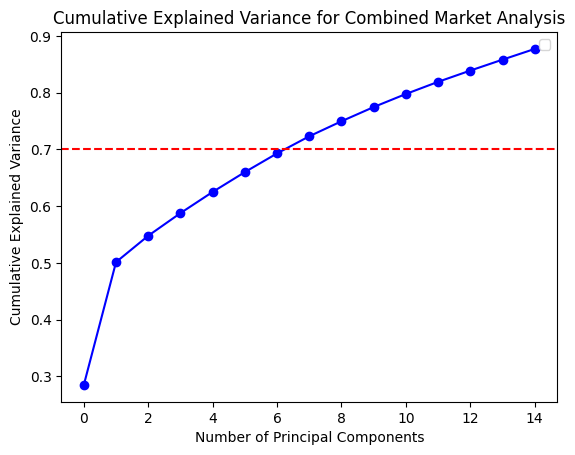
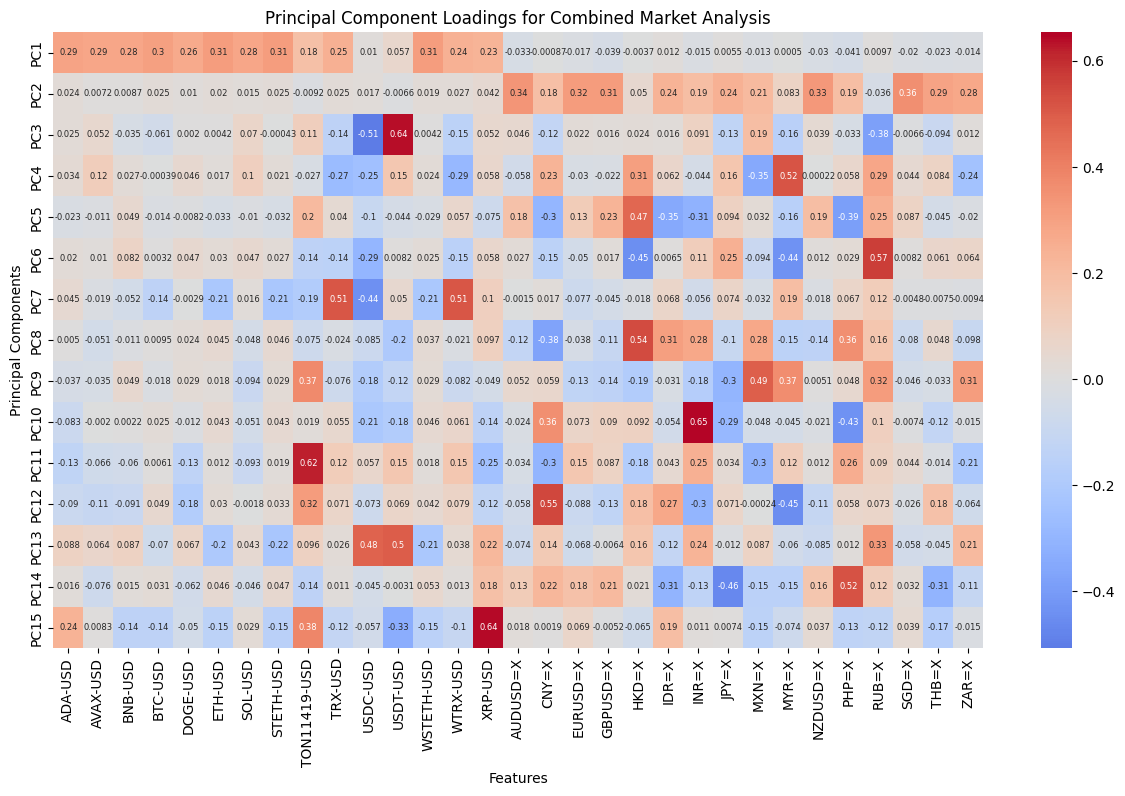
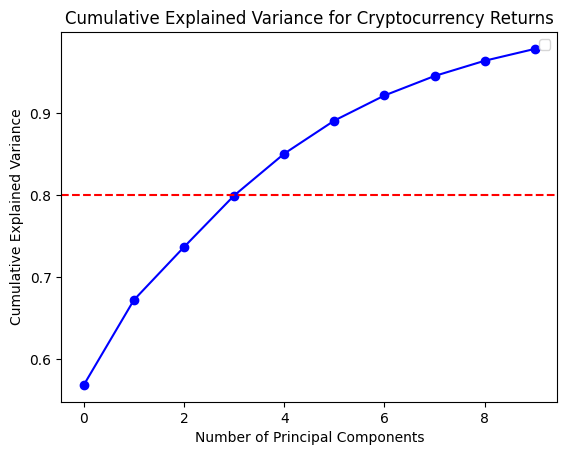
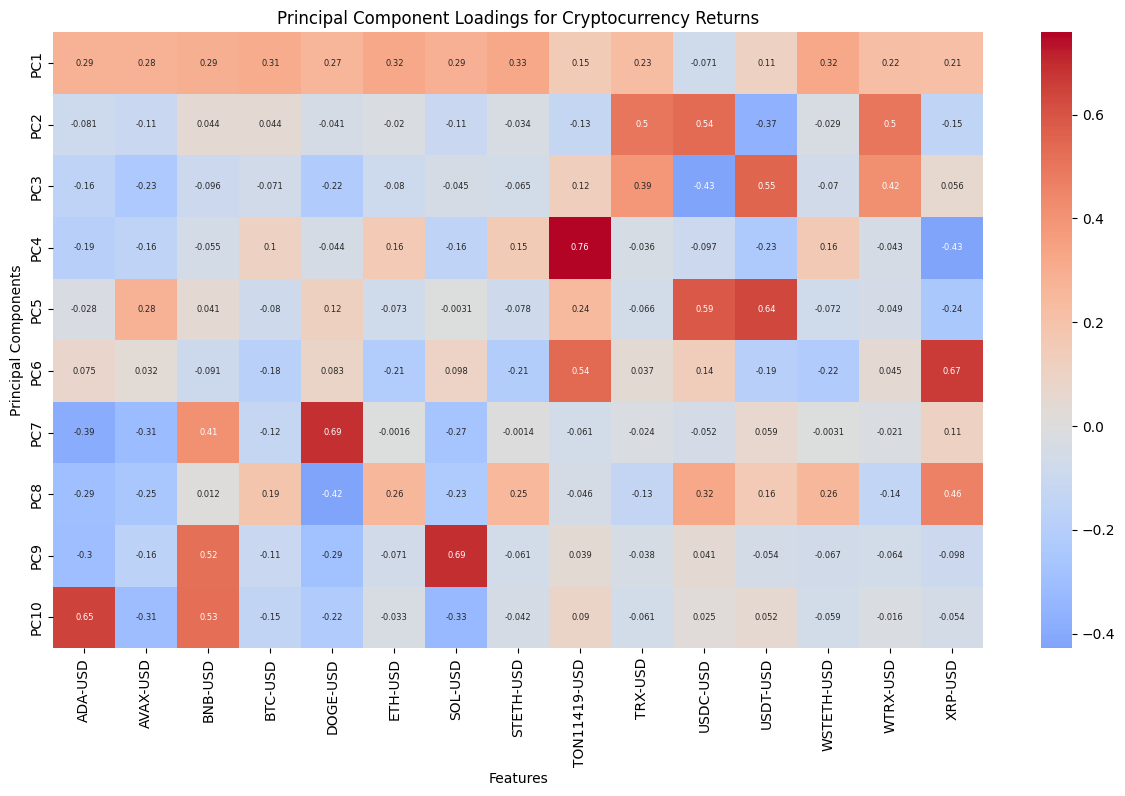
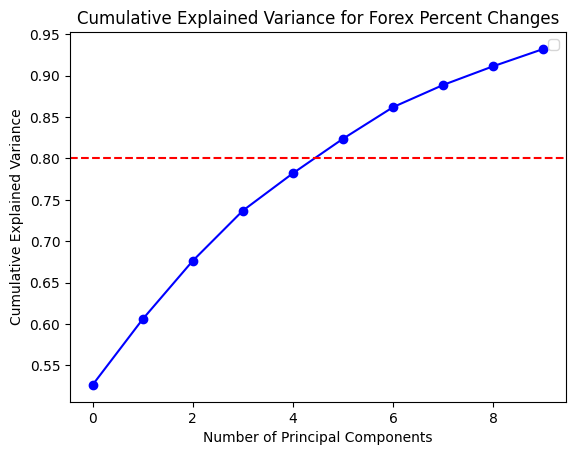
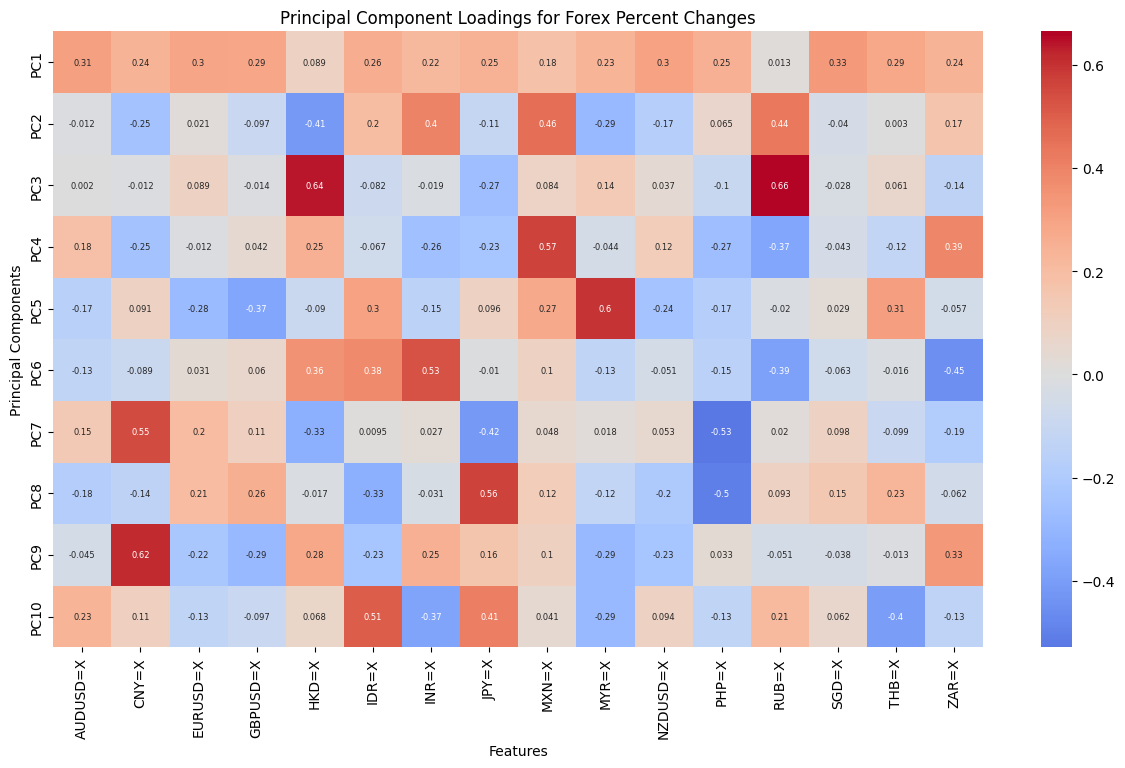
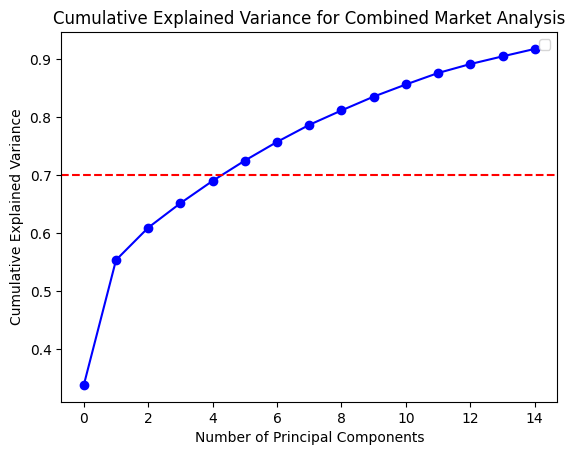
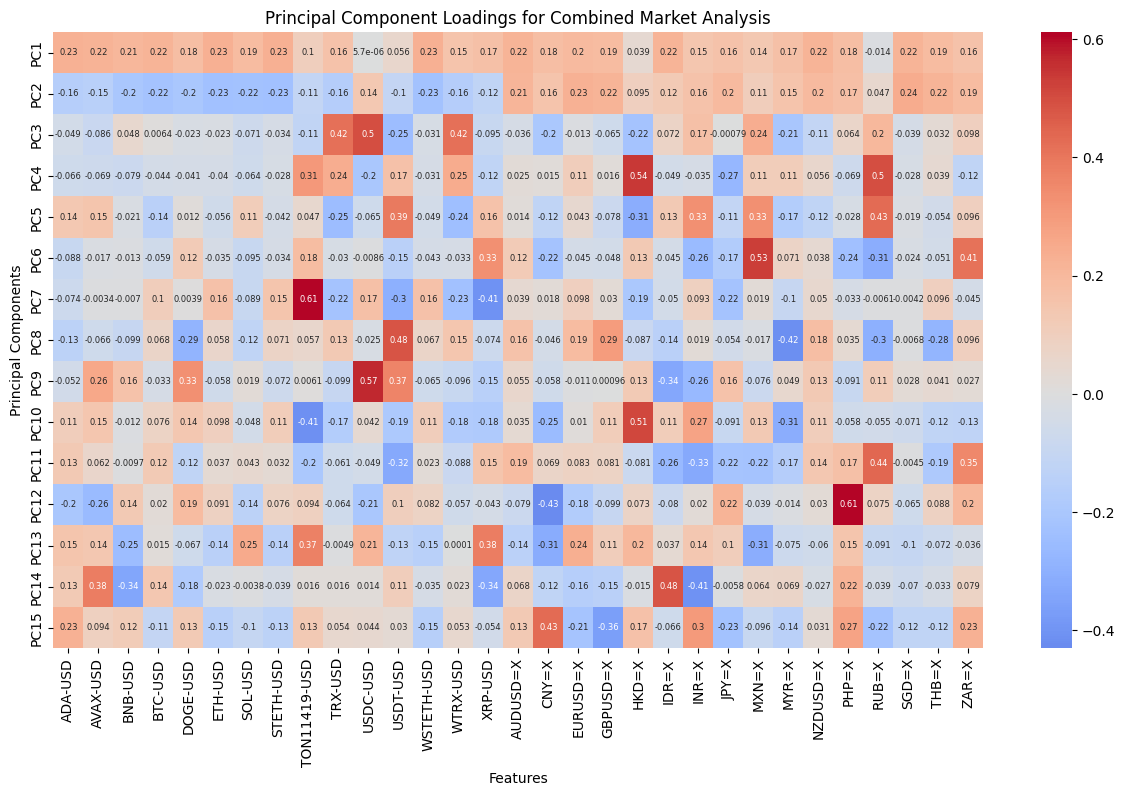
In order to gain a deeper comprehension of the underlying significance of the principal components, we proceed to define the functions utilized for the calculation and visualization of the loadings. In order to accommodate the heightened complexity of the feature dimensions, a threshold of 80% for both markets and 70% for the composite market was established for the cumulative explained variance. In conclusion, the optimal principal component scores for each dataset have been derived. Subsequently, the loading matrices were generated and visualized in the form of heatmaps, thereby facilitating an understanding of the weighting of each feature in the principal components.
The preceding analysis demonstrates that the first principal component captures the majority of the variance in both cryptocurrency and FX data. However, the former exhibits a stronger correlation with intra-market volatility, while the latter demonstrates a relatively more even distribution of variance, indicating that the correlation within the FX market is lower. With regard to the aggregate market, the cryptocurrency feature tends to exert a greater influence on the initial principal components, whereas the reverse is true for the FX feature. These findings provide a more profound comprehension of the data structure, thereby establishing a foundation for the subsequent selection of classification criteria.
# Function to calculate and visualize PCA loadingsdef plot_pca_loadings(data, title, threshold=0.8, n=10): scaler = StandardScaler() data_scaled = scaler.fit_transform(data.drop(columns=['Date'])) pca = PCA(n_components=n) pca.fit(data_scaled)# Explained variance ratio explained_variance = pca.explained_variance_ratio_ cumulative_variance = explained_variance.cumsum()# Find the optimal number of components optimal_components = (cumulative_variance >= threshold).argmax() +1print(f"Optimal number of components: {optimal_components}")# Plot cumulative explained variance plt.plot(cumulative_variance, marker='o', color='blue') plt.axhline(y=threshold, color='red', linestyle='dashed') plt.title(f'Cumulative Explained Variance for {title}') plt.xlabel('Number of Principal Components') plt.ylabel('Cumulative Explained Variance') plt.legend() plt.show()# Create loadings DataFrame loadings_df = pd.DataFrame( data=pca.components_, columns=data.drop(columns=['Date']).columns, index=[f'PC{i+1}'for i inrange(pca.n_components_)] )print(loadings_df)# Visualization plt.figure(figsize=(15, 8)) sns.heatmap(loadings_df, cmap='coolwarm', annot=True, center=0, annot_kws={"size": 6}) plt.title(f'Principal Component Loadings for {title}') plt.xlabel('Features') plt.ylabel('Principal Components') plt.show()return loadings_dfplot_pca_loadings(crypto_filtered, "Cryptocurrency Returns", threshold=0.8, n=10)plot_pca_loadings(fx_filtered, "Forex Percent Changes", threshold=0.8, n=10)plot_pca_loadings(combined_data, "Combined Market Analysis", threshold=0.7, n=15)
Optimal number of components: 5
/tmp/ipykernel_876/2038098554.py:22: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
/tmp/ipykernel_876/2038098554.py:22: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
/tmp/ipykernel_876/2038098554.py:22: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
# Function to calculate and visualize PCA loadingsdef plot_pca_loadings(data, title, threshold=0.8, n=10): scaler = StandardScaler() data_scaled = scaler.fit_transform(data.drop(columns=['Date'])) pca = PCA(n_components=n) pca.fit(data_scaled)# Explained variance ratio explained_variance = pca.explained_variance_ratio_ cumulative_variance = explained_variance.cumsum()# Find the optimal number of components optimal_components = (cumulative_variance >= threshold).argmax() +1print(f"Optimal number of components: {optimal_components}")# Plot cumulative explained variance plt.plot(cumulative_variance, marker='o', color='blue') plt.axhline(y=threshold, color='red', linestyle='dashed') plt.title(f'Cumulative Explained Variance for {title}') plt.xlabel('Number of Principal Components') plt.ylabel('Cumulative Explained Variance') plt.legend() plt.show()# Create loadings DataFrame loadings_df = pd.DataFrame( data=pca.components_, columns=data.drop(columns=['Date']).columns, index=[f'PC{i+1}'for i inrange(pca.n_components_)] )print(loadings_df)# Visualization plt.figure(figsize=(15, 8)) sns.heatmap(loadings_df, cmap='coolwarm', annot=True, center=0, annot_kws={"size": 6}) plt.title(f'Principal Component Loadings for {title}') plt.xlabel('Features') plt.ylabel('Principal Components') plt.show()return loadings_dfplot_pca_loadings(crypto_filtered_w, "Cryptocurrency Returns", threshold=0.8, n=10)plot_pca_loadings(fx_filtered_w, "Forex Percent Changes", threshold=0.8, n=10)plot_pca_loadings(combined_data_w, "Combined Market Analysis", threshold=0.7, n=15)
Optimal number of components: 5
/tmp/ipykernel_876/222584158.py:22: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
/tmp/ipykernel_876/222584158.py:22: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
/tmp/ipykernel_876/222584158.py:22: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
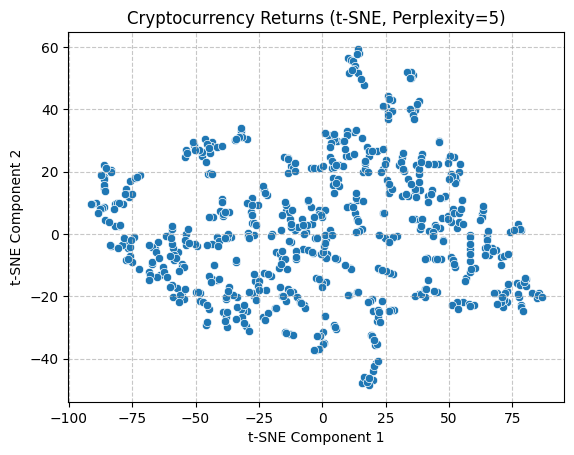
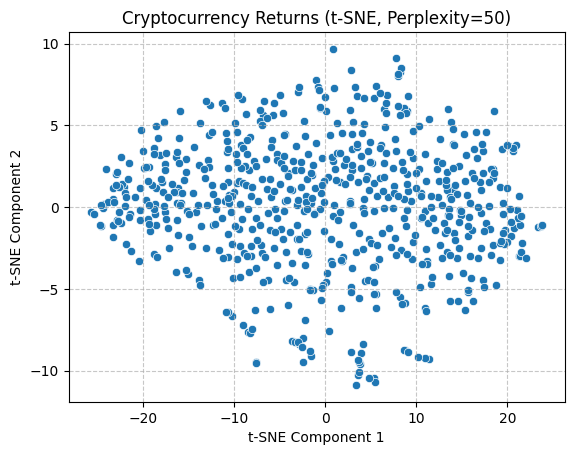
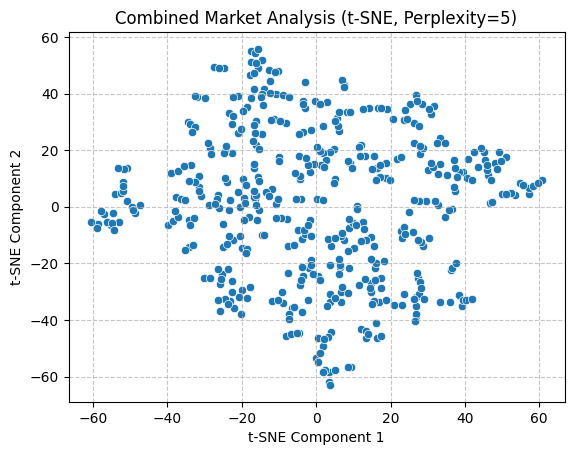
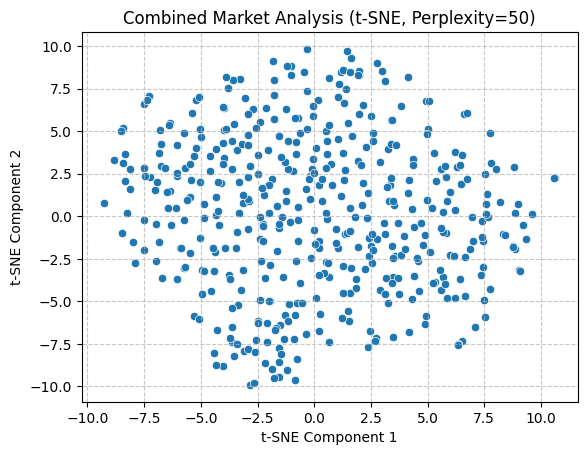
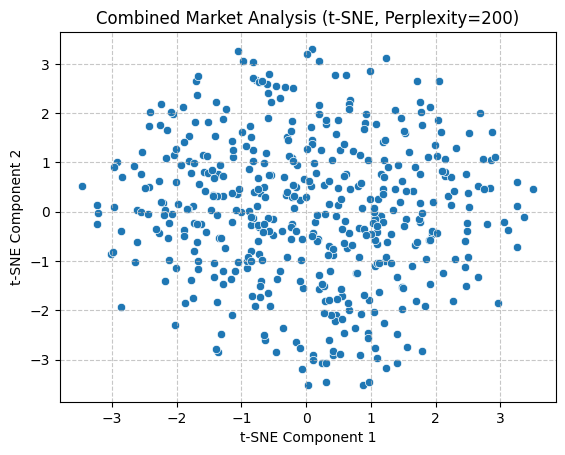
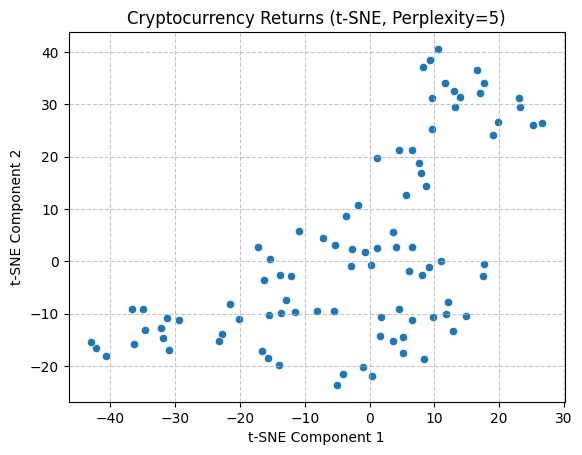
Following an initial trial of linear techniques, a nonlinear t-SNE approach was employed to facilitate the exploration of data relationships and patterns. To obtain a more comprehensive understanding, separate analysis were conducted with perplexity values of 5, 50, and 200. Similarly, following data normalization, the data were reduced to two dimensions and visualized in the form of scatter plots. As can be observed, the application of multiple perplexity still results in the absence of discernible intermarket patterns.
With regard to preserving data structure, PCA exhibited superior performance, as evidenced by its capacity to illustrate the distribution of variance. Conversely, the implementation of t-SNE in the present study did not permit the observation of notable inter-market clustering. Moreover, the two methods differed in their visualisation focus. In conclusion, the joint application of the two methods offers a more comprehensive analytical perspective for subsequent unsupervised learning analysis.
Clustering
The application of clustering techniques can facilitate the exploration of underlying patterns within datasets. The identification of cluster structures may, in turn, facilitate a more profound understanding of market dynamics and the analysis of data for groupable qualities. Three clustering approaches were employed: K-means, DBSCAN and hierarchical clustering.
K-Means
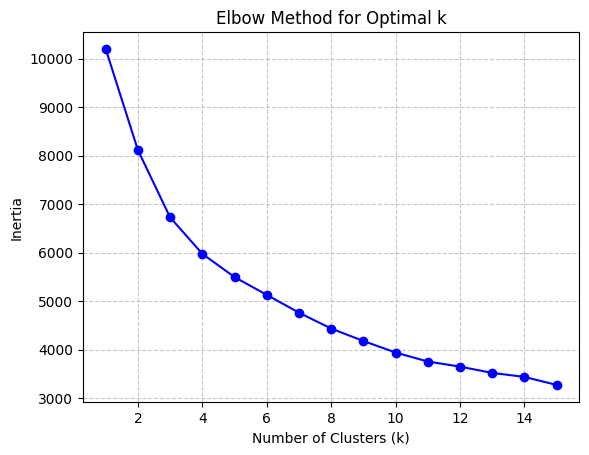
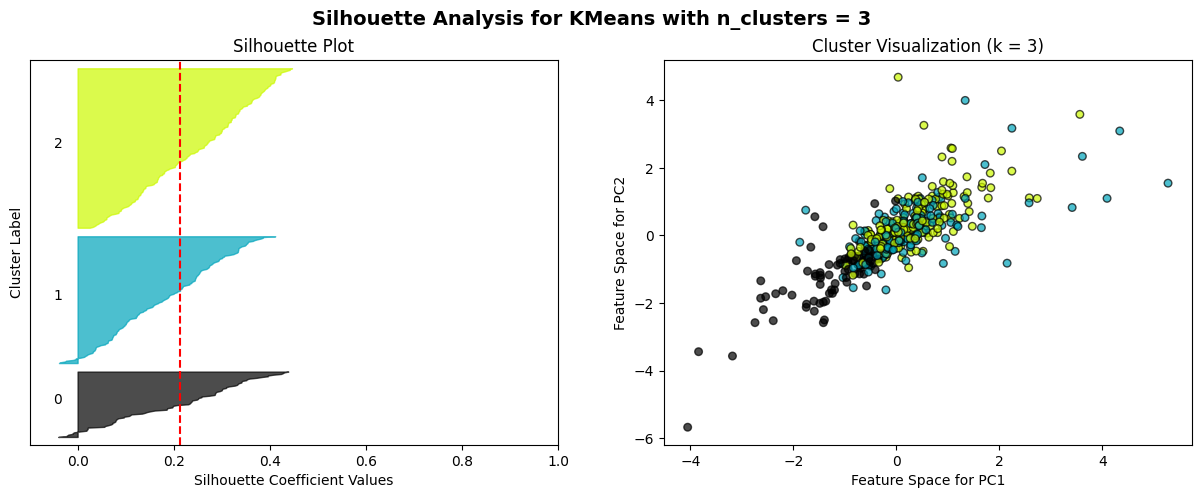
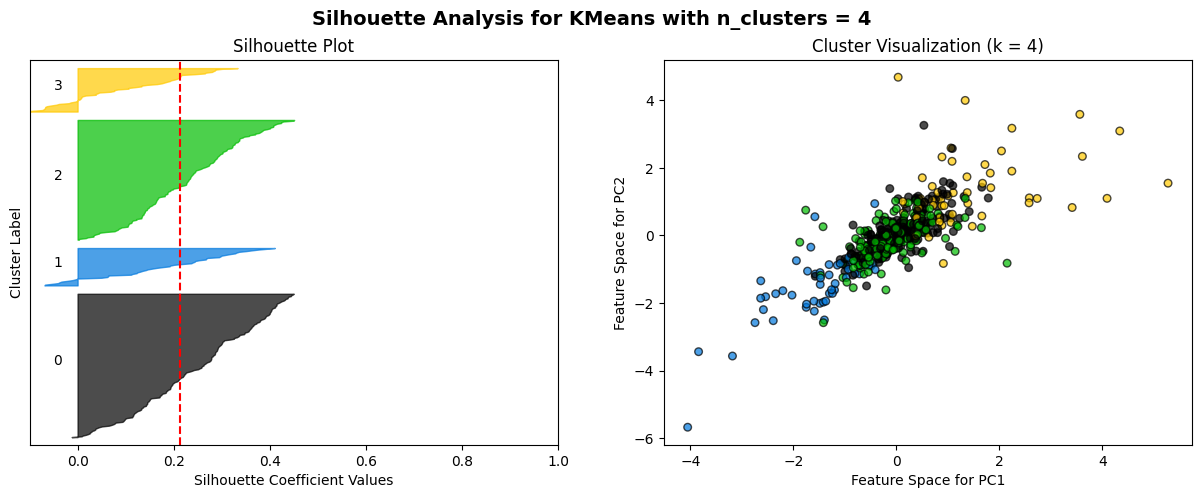
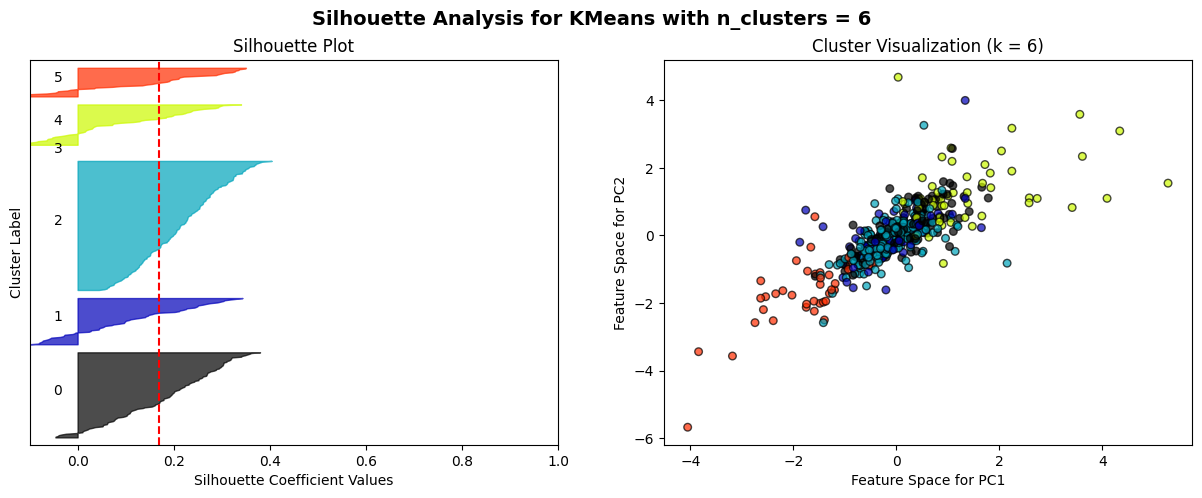
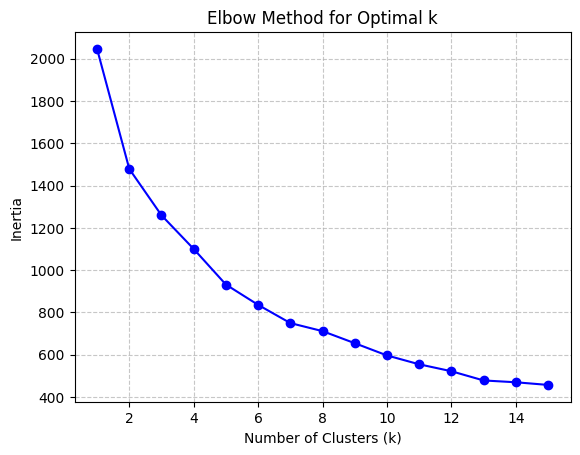
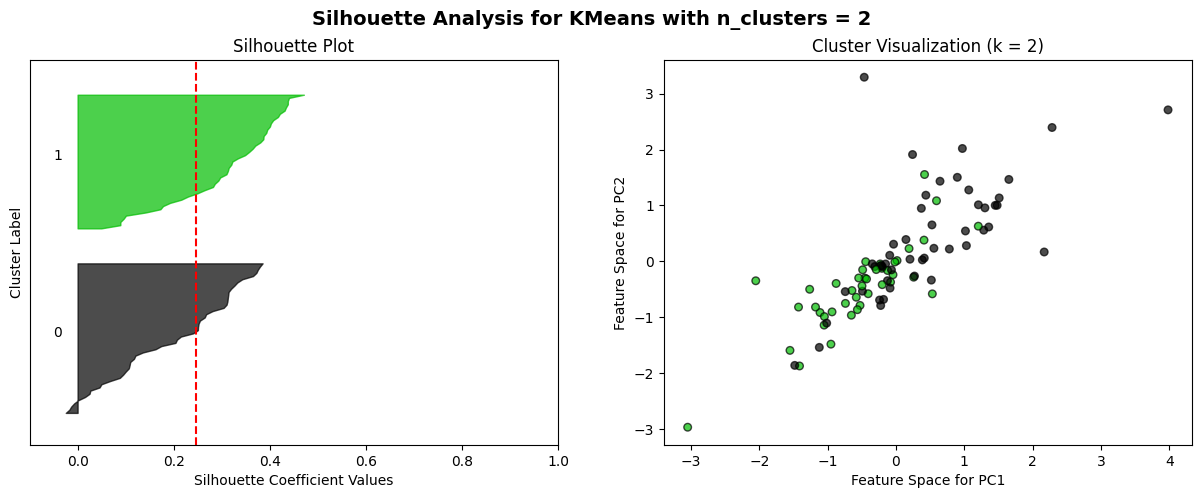
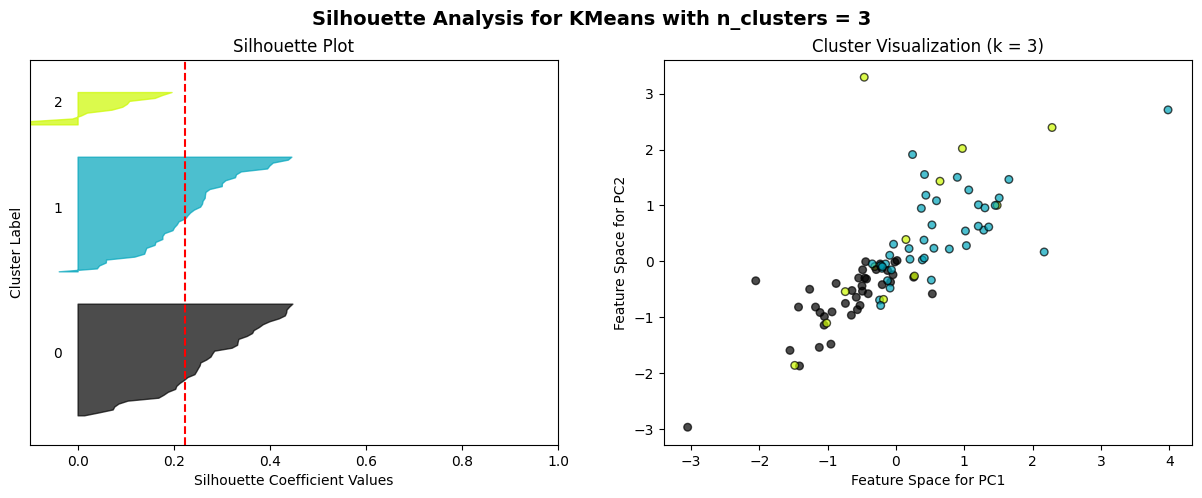
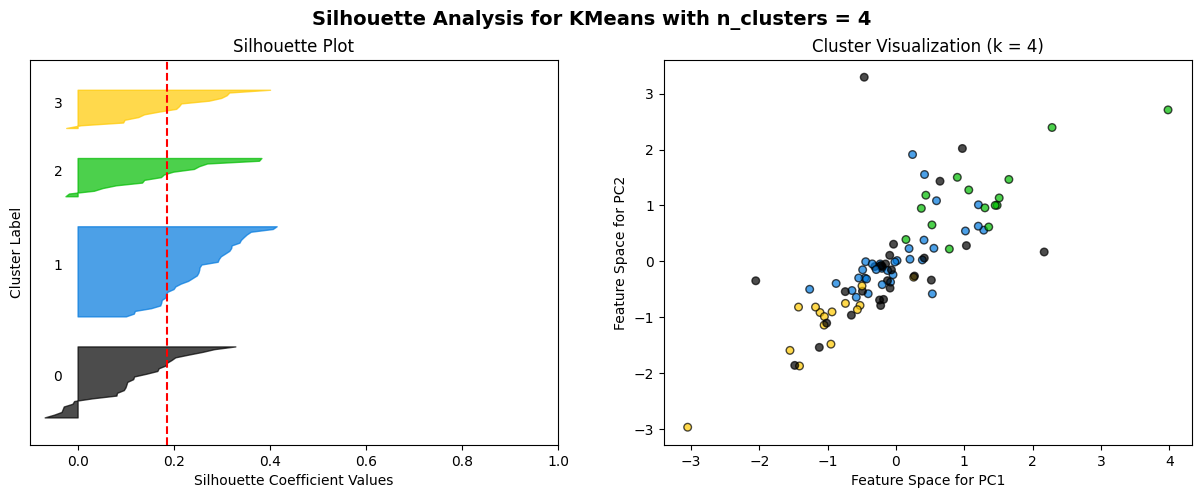
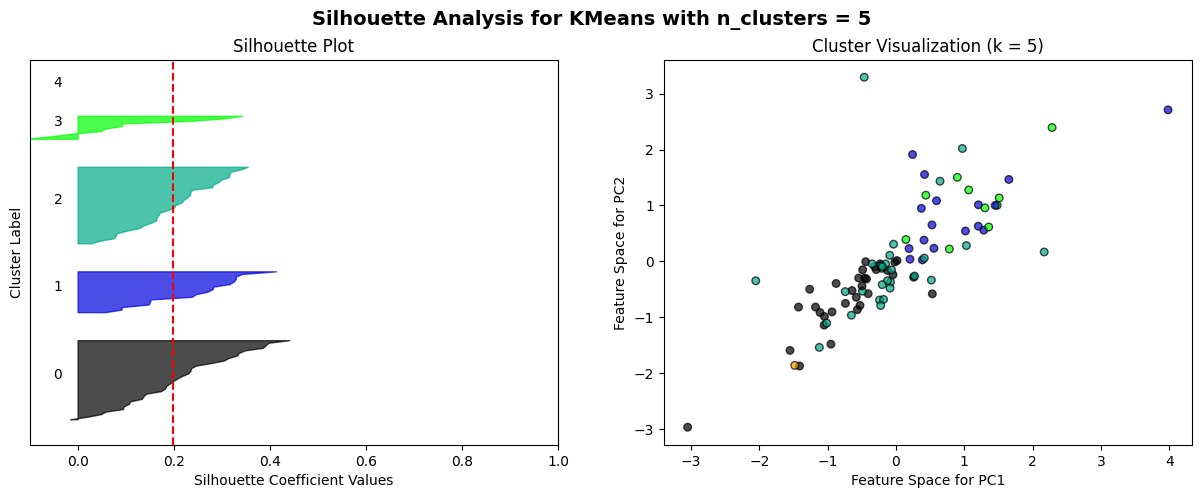
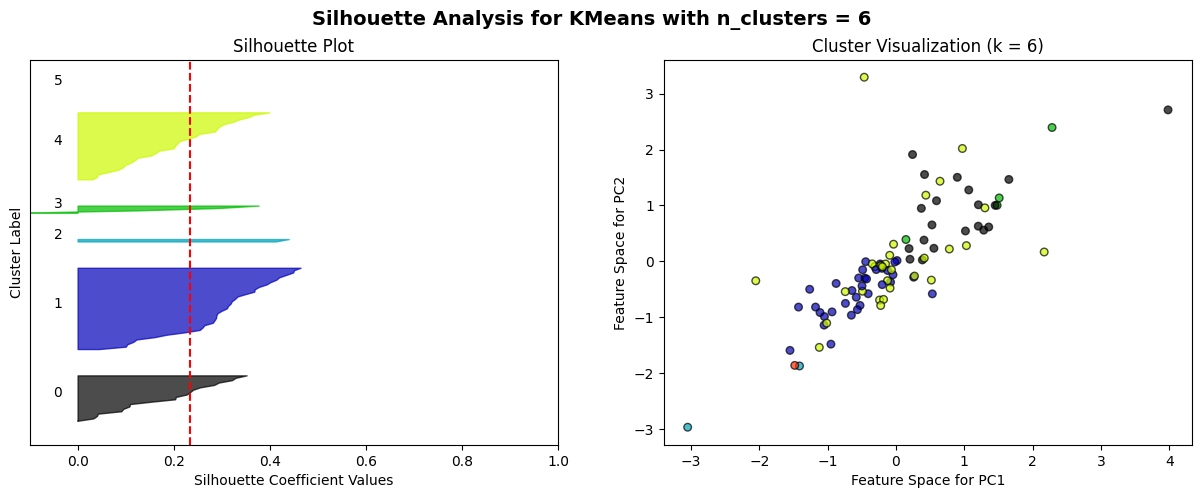
The K-means algorithm is employed to partition clusters through the calculation and minimization of the distance between data points and their nearest clustering centres. The process commences with the random selection of k initial centroids, which are then iterated with continuous updating until no further changes are observed. A combination of the elbow method and the Silhouette score method is employed as a means of selecting an appropriate model. The elbow method is a technique for identifying the optimal value of k at the inflection point of the curve. This is achieved by calculating the inertia values for various values of k and plotting the resulting curve. The Silhouette score method is a method for evaluating the fitness of a model. This is done by calculating Silhouette scores (ranging from -1 to 1) for each data point at different values of k. The higher the score, the more accurately the clusters are categorized.
The elbow method curve was used to determine that the number of clusters that may be appropriate is 2, 3, 4, 5, and 6. A Silhouette score analysis was then performed on these k values, which demonstrated that the profile coefficients were relatively high for k=3 for daily data and k=2 for weekly data. However, the difference was not statistically significant, and no discernible cluster boundaries could be observed in the cluster scatterplot. This further suggests that the volatility data of the two markets most likely do not have a clear linear grouping.
For n_clusters = 2, the average silhouette_score is: 0.2467938250235648
For n_clusters = 3, the average silhouette_score is: 0.22325228349628845
For n_clusters = 4, the average silhouette_score is: 0.1855574332777159
For n_clusters = 5, the average silhouette_score is: 0.19874340001005872
For n_clusters = 6, the average silhouette_score is: 0.23421955294037305
DBSCAN
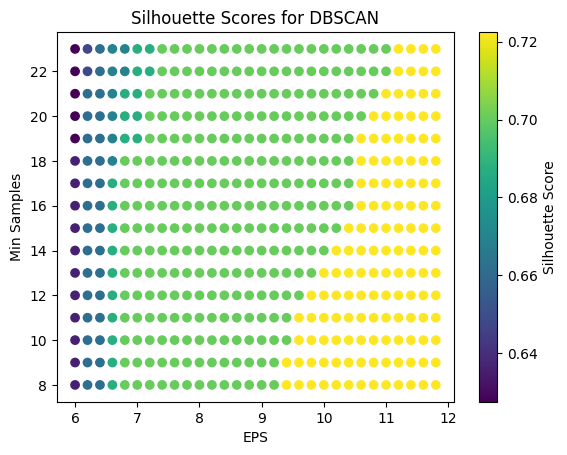
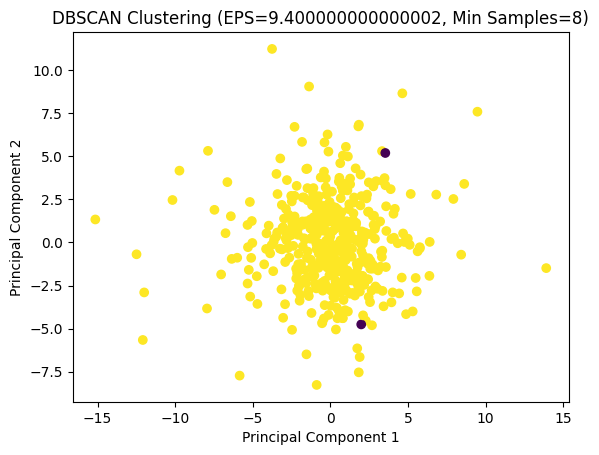
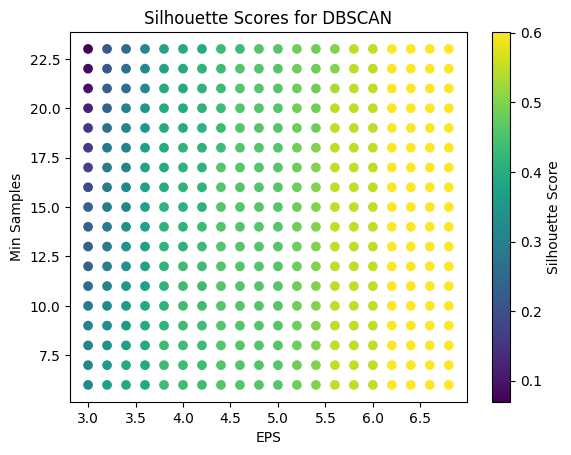
The DBSCAN technique is employed to identify clusters and noise points through the utilization of density connections. In order to determine the search radius and the minimum number of points in the clusters, two parameters are required: the domain radius, denoted as EPS, and the minimum number of samples. Similarly, the Silhouette Score method was employed for the purpose of tuning the parameters and optimizing the model.
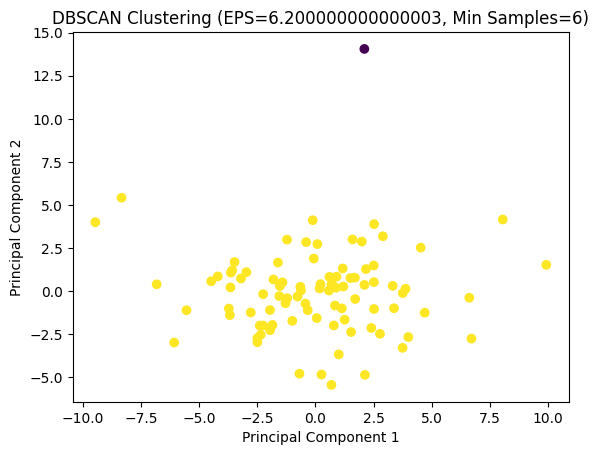
A variety of parameter ranges were tested, resulting in the identification of the optimal parameter settings and model. Despite the Silhouette Score of 0.7224 for daily data and 0.6008 for weekly data, the visualization indicates that the clustering is not particularly effective, which may suggest that it is challenging to identify meaningful groupings for the data from the two markets under this dimension.
Data shape: (91, 6)
Optimal EPS: 6.200000000000003
Optimal Min Samples: 6
Maximum Silhouette Score: 0.6008
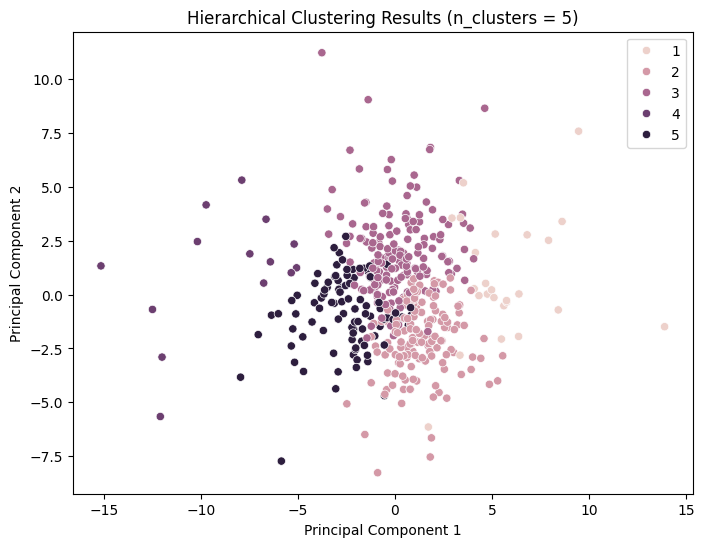
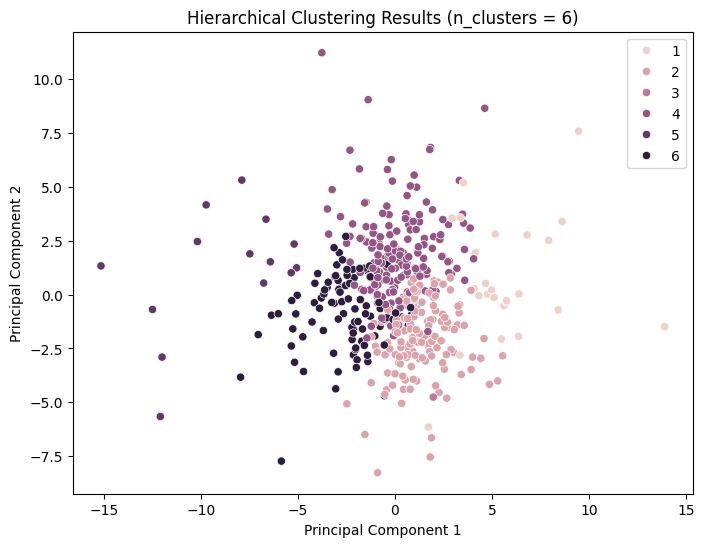
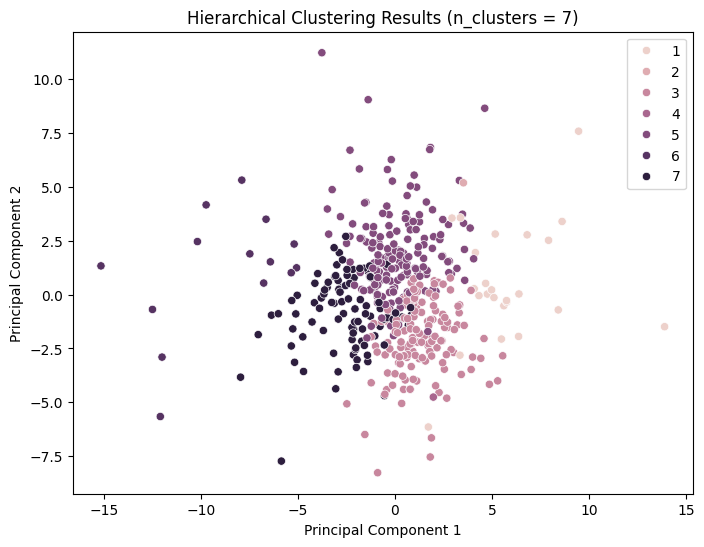
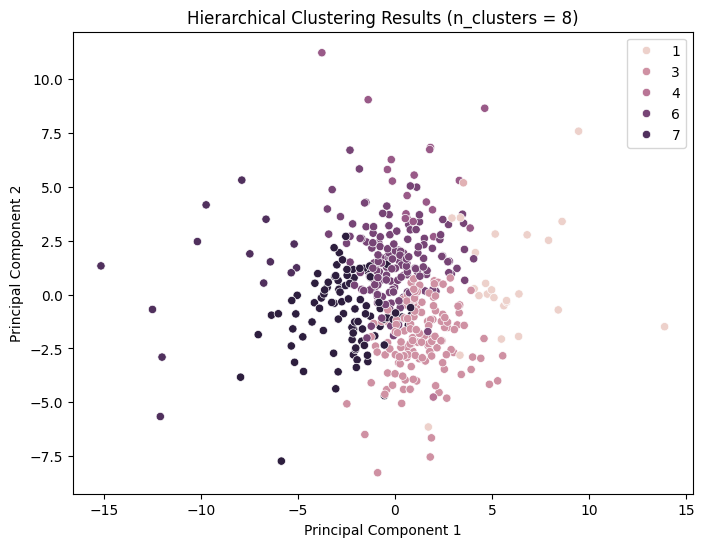
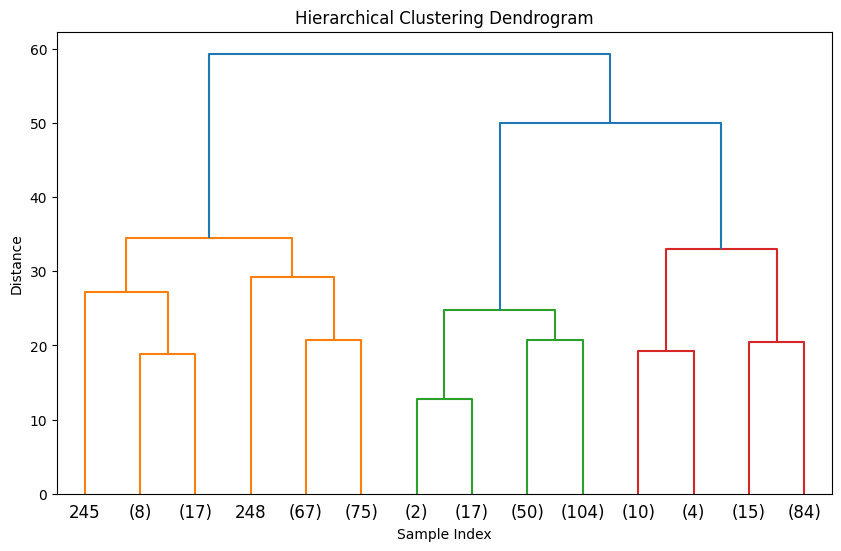
Hierarchical Clustering
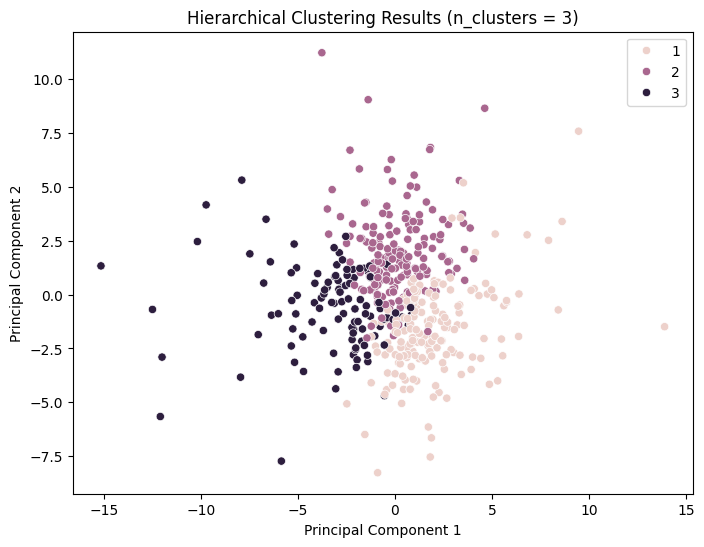
Hierarchical clustering techniques facilitate the generation of tree-structured data hierarchies through recursive processes, obviating the need for input parameters such as the number of clusters. The Ward clustering algorithm was employed, and the silhouette score method was used to evaluate the model performance.
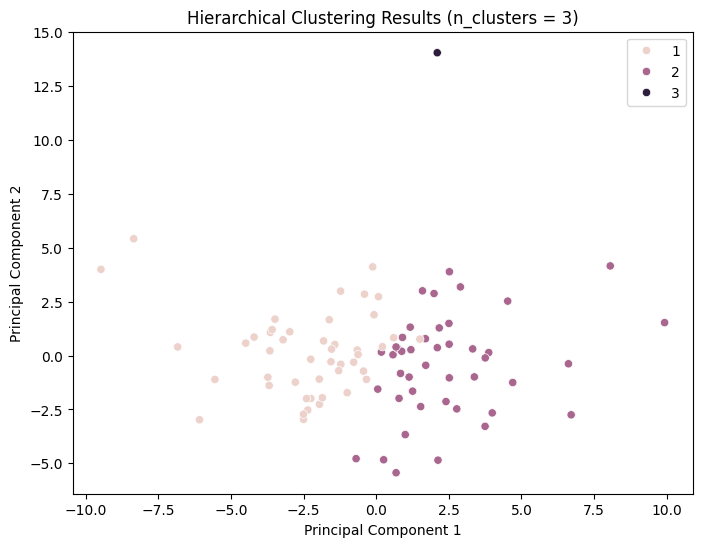
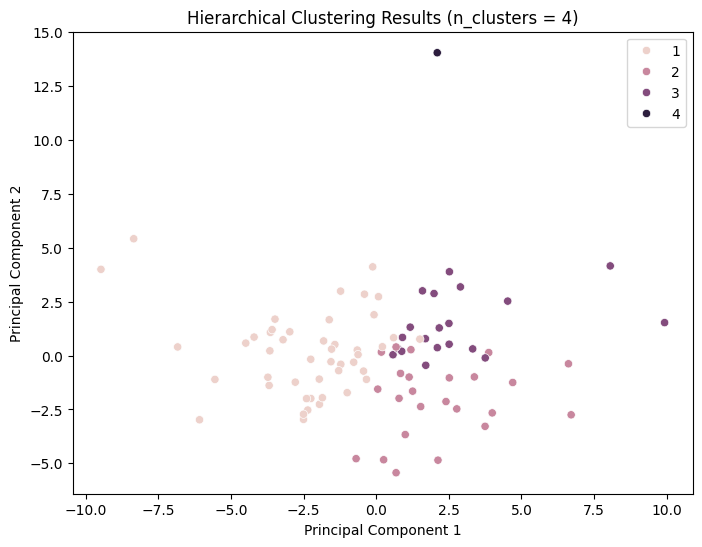
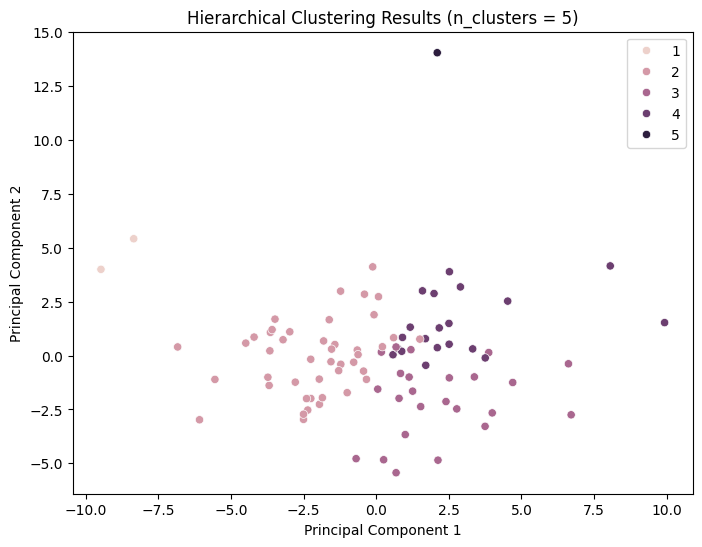
It can be observed that the silhouette scores attain relatively high values for n_cluster=3; nevertheless, the clustering effect remains inadequate.
For n_clusters = 3, the average silhouette_score is: 0.24042273382355286
For n_clusters = 4, the average silhouette_score is: 0.20099230051589648
For n_clusters = 5, the average silhouette_score is: 0.2116560825886306
For n_clusters = 6, the average silhouette_score is: 0.16203171542422257
For n_clusters = 7, the average silhouette_score is: 0.16757694754407834
For n_clusters = 8, the average silhouette_score is: 0.16776830800478731
Conclusion
By comparing the results of the above three clustering methods we can find that the combined performance of K-means is relatively good, while the results of DBSCAN show that the data does not have much density clustering properties. Overall, we all have difficulty in recognizing clear grouping patterns in the combined market data. This suggests that the data still lacks clear boundary separation after dimensionality reduction.
From a practical application point of view, we can assume that the volatility of the cryptocurrency market and the foreign exchange market in general has no obvious direct correlation. The volatility of the two may be affected by a large number of complex factors, which makes it difficult to find patterns through simple dimensionality reduction and clustering methods, which is also in line with the nature of the financial market data that is difficult to predict. In the subsequent supervised learning analysis, we will try to group the results based on the PCA in this section to introduce more features and observe whether there are localized volatility correlations.